


Understanding LoRA?—?Low Rank Adaptation For Finetuning Large ModelsMath behind this parameter efficient finetuning methodFine-tuning large pre-trained models is computationally challenging, often involving adjustment of millions of parameters. This traditional fine-tuning approach, while effective, demands substantial computational resources and time, posing...
Understanding LoRA?—?Low Rank Adaptation For Finetuning Large Models
Math behind this parameter efficient finetuning method
Fine-tuning large pre-trained models is computationally challenging, often involving adjustment of millions of parameters. This traditional fine-tuning approach, while effective, demands substantial computational resources and time, posing a bottleneck for adapting these models to specific tasks. LoRA presented an effective solution to this problem by decomposing the update matrix during finetuing. To study LoRA, let us start by first revisiting traditional finetuing.
Decomposition of ( ? W )
In traditional fine-tuning, we modify a pre-trained neural network’s weights to adapt to a new task. This adjustment involves altering the original weight matrix ( W ) of the network. The changes made to ( W ) during fine-tuning are collectively represented by ( ? W ), such that the updated weights can be expressed as ( W + ? W ).
Now, rather than modifying ( W ) directly, the LoRA approach seeks to decompose ( ? W ). This decomposition is a crucial step in reducing the computational overhead associated with fine-tuning large models.
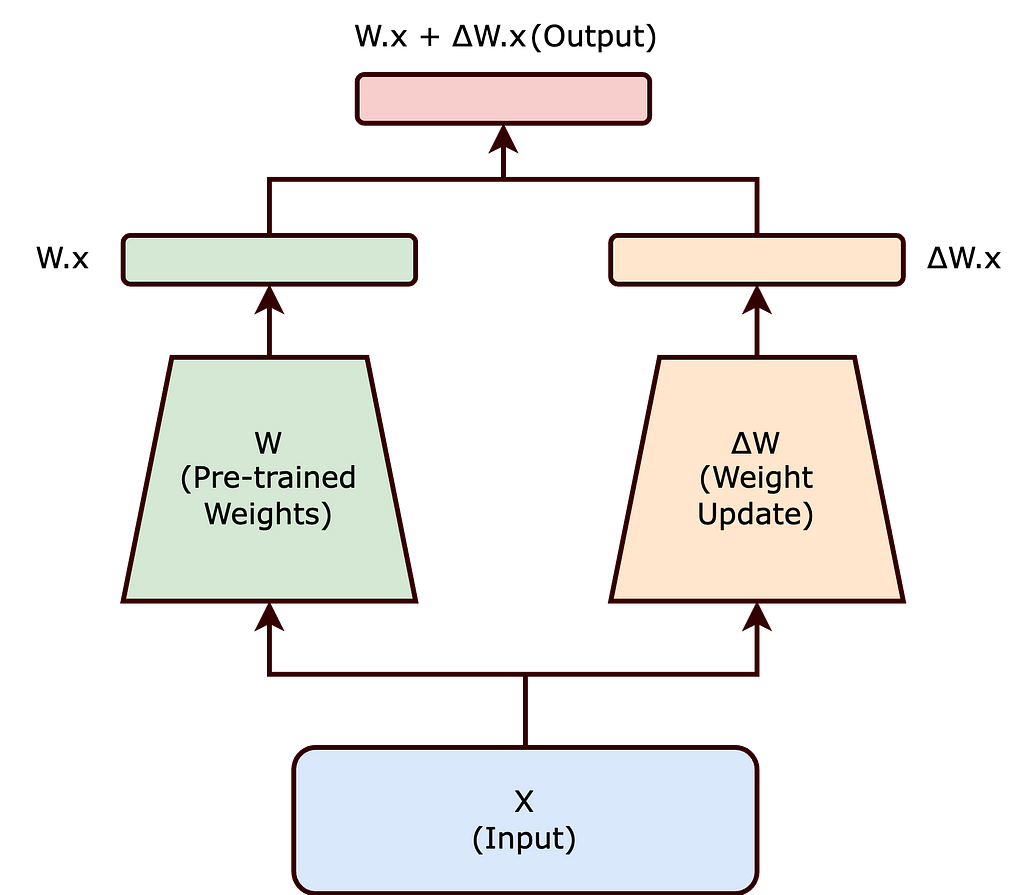 Traditional finetuning can be reimagined us above. Here W is frozen where as ?W is trainable (Image by the blog author)
Traditional finetuning can be reimagined us above. Here W is frozen where as ?W is trainable (Image by the blog author)The Intrinsic Rank Hypothesis
The intrinsic rank hypothesis suggests that significant changes to the neural network can be captured using a lower-dimensional representation. Essentially, it posits that not all elements of ( ? W ) are equally important; instead, a smaller subset of these changes can effectively encapsulate the necessary adjustments.
Introducing Matrices ( A ) and ( B )
Building on this hypothesis, LoRA proposes representing ( ? W ) as the product of two smaller matrices, ( A ) and ( B ), with a lower rank. The updated weight matrix ( W’ ) thus becomes:
[ W’ = W + BA ]
In this equation, ( W ) remains frozen (i.e., it is not updated during training). The matrices ( B ) and ( A ) are of lower dimensionality, with their product ( BA ) representing a low-rank approximation of ( ? W ).
 ?W is decomposed into two matrices A and B where both have lower dimensionality then d x d. (Image by the blog author)
?W is decomposed into two matrices A and B where both have lower dimensionality then d x d. (Image by the blog author)Impact of Lower Rank on Trainable Parameters
By choosing matrices ( A ) and ( B ) to have a lower rank ( r ), the number of trainable parameters is significantly reduced. For example, if ( W ) is a ( d x d ) matrix, traditionally, updating ( W ) would involve ( d˛ ) parameters. However, with ( B ) and ( A ) of sizes ( d x r ) and ( r x d ) respectively, the total number of parameters reduces to ( 2dr ), which is much smaller when ( r << d ).
The reduction in the number of trainable parameters, as achieved through the Low-Rank Adaptation (LoRA) method, offers several significant benefits, particularly when fine-tuning large-scale neural networks:
Reduced Memory Footprint: LoRA decreases memory needs by lowering the number of parameters to update, aiding in the management of large-scale models.Faster Training and Adaptation: By simplifying computational demands, LoRA accelerates the training and fine-tuning of large models for new tasks.Feasibility for Smaller Hardware: LoRA’s lower parameter count enables the fine-tuning of substantial models on less powerful hardware, like modest GPUs or CPUs.Scaling to Larger Models: LoRA facilitates the expansion of AI models without a corresponding increase in computational resources, making the management of growing model sizes more practical.In the context of LoRA, the concept of rank plays a pivotal role in determining the efficiency and effectiveness of the adaptation process. Remarkably, the paper highlights that the rank of the matrices A and B can be astonishingly low, sometimes as low as one.
Although the LoRA paper predominantly showcases experiments within the realm of Natural Language Processing (NLP), the underlying approach of low-rank adaptation holds broad applicability and could be effectively employed in training various types of neural networks across different domains.
Conclusion
LoRA’s approach to decomposing ( ? W ) into a product of lower rank matrices effectively balances the need to adapt large pre-trained models to new tasks while maintaining computational efficiency. The intrinsic rank concept is key to this balance, ensuring that the essence of the model’s learning capability is preserved with significantly fewer parameters.
Understanding LoRA?—?Low Rank Adaptation For Finetuning Large Models was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.