Learn how to utilize LLMs to answer user questions based on ingested PDFs at runtime. Accelerate generative AI innovation and real-world value using DataRobot�s GenAI Accelerators. The post Deep Dive into JITR: The PDF Ingesting and Querying Generative AI...
Motivation
Accessing, understanding, and retrieving information from documents are central to countless processes across various industries. Whether working in finance, healthcare, at a mom and pop carpet store, or as a student in a University, there are situations where you see a big document that you need to read through to answer questions. Enter JITR, a game-changing tool that ingests PDF files and leverages LLMs (Language Language Models) to answer user queries about the content. Let�s explore the magic behind JITR.
What Is JITR?
JITR, which stands for Just In Time Retrieval, is one of the newest tools in DataRobot�s GenAI Accelerator suite designed to process PDF documents, extract their content, and deliver accurate answers to user questions and queries. Imagine having a personal assistant that can read and understand any PDF document and then provide answers to your questions about it instantly. That�s JITR for you.
How Does JITR Work?
Ingesting PDFs: The initial stage involves ingesting a PDF into the JITR system. Here, the tool converts the static content of the PDF into a digital format ingestible by the embedding model. The embedding model converts each sentence in the PDF file into a vector. This process creates a vector database of the input PDF file.
Applying your LLM: Once the content is ingested, the tool calls the LLM. LLMs are state-of-the-art AI models trained on vast amounts of text data. They excel at understanding context, discerning meaning, and generating human-like text. JITR employs these models to understand and index the content of the PDF.
Interactive Querying: Users can then pose questions about the PDF�s content. The LLM fetches the relevant information and presents the answers in a concise and coherent manner.
Benefits of Using JITR
Every organization produces a variety of documents that are generated in one department and consumed by another. Often, retrieval of information for employees and teams can be time consuming. Utilization of JITR improves employee efficiency by reducing the review time of lengthy PDFs and providing instant and accurate answers to their questions. In addition, JITR can handle any type of PDF content which enables organizations to embed and utilize it in different workflows without concern for the input document.�
Many organizations may not have resources and expertise in software development to develop tools that utilize LLMs in their workflow. JITR enables teams and departments that are not fluent in Python to convert a PDF file into a vector database as context for an LLM. By simply having an endpoint to send PDF files to, JITR can be integrated into any web application such as Slack (or other messaging tools), or external portals for customers. No knowledge of LLMs, Natural Language Processing (NLP), or vector databases is required.
Real-World Applications
Given its versatility, JITR can be integrated into almost any workflow. Below are some of the applications.
Business Report: Professionals can swiftly get insights from lengthy reports, contracts, and whitepapers. Similarly, this tool can be integrated into internal processes, enabling employees and teams to interact with internal documents.��
Customer Service: From understanding technical manuals to diving deep into tutorials, JITR can enable customers to interact with manuals and documents related to the products and tools. This can increase customer satisfaction and reduce the number of support tickets and escalations.�
Research and Development: R&D teams can quickly extract relevant and digestible information from complex research papers to implement the State-of-the-art technology in the product or internal processes.
Alignment with Guidelines: Many organizations have guidelines that should be followed by employees and teams. JITR enables employees to retrieve relevant information from the guidelines efficiently.�
Legal: JITR can ingest legal documents and contracts and answer questions based on the information provided in the input documents.
How to Build the JITR Bot with DataRobot
The workflow for building a JITR Bot is similar to the workflow for deploying any LLM pipeline using DataRobot. The two main differences are:
Your vector database is defined at runtime You need logic to handle an encoded PDFFor the latter we can define a simple function that takes an encoding and writes it back to a temporary PDF file within our deployment.
```python def base_64_to_file(b64_string, filename: str='temp.PDF', directory_path: str = "./storage/data") -> str:����� ����"""Decode a base64 string into a PDF file""" ����import os ����if not os.path.exists(directory_path): ��������os.makedirs(directory_path) ����file_path = os.path.join(directory_path, filename) ����with open(file_path, "wb") as f: ��������f.write(codecs.decode(b64_string, "base64"))��� ����return file_path ```With this helper function defined we can go through and make our hooks. Hooks are just a fancy phrase for functions with a specific name. In our case, we just need to define a hook called `load_model` and another hook called `score_unstructured`.� In `load_model`, we�ll set the embedding model we want to use to find the most relevant chunks of text as well as the LLM we�ll ping with our context aware prompt.
```python def load_model(input_dir): ����"""Custom model hook for loading our knowledge base.""" ����import os ����import datarobot_drum as drum ����from langchain.chat_models import AzureChatOpenAI ����from langchain.embeddings.sentence_transformer import SentenceTransformerEmbeddings ����try: ��������# Pull credentials from deployment ��������key = drum.RuntimeParameters.get("OPENAI_API_KEY")["apiToken"] ����except ValueError: ��������# Pull credentials from environment (when running locally) ��������key = os.environ.get('OPENAI_API_KEY', '') ����embedding_function = SentenceTransformerEmbeddings( ��������model_name="all-MiniLM-L6-v2", ��������cache_folder=os.path.join(input_dir, 'storage/deploy/sentencetransformers') ����) ����llm = AzureChatOpenAI( ��������deployment_name=OPENAI_DEPLOYMENT_NAME, ��������openai_api_type=OPENAI_API_TYPE, ��������openai_api_base=OPENAI_API_BASE, ��������openai_api_version=OPENAI_API_VERSION, ��������openai_api_key=OPENAI_API_KEY, ��������openai_organization=OPENAI_ORGANIZATION, ��������model_name=OPENAI_DEPLOYMENT_NAME, ��������temperature=0, ��������verbose=True ����) ����return llm, embedding_function ```Ok, so we have our embedding function and our LLM. We also have a way to take an encoding and get back to a PDF. So now we get to the meat of the JITR Bot, where we�ll build our vector store at run time and use it to query the LLM.
```python def score_unstructured(model, data, query, **kwargs) -> str: ����"""Custom model hook for making completions with our knowledge base. ����When requesting predictions from the deployment, pass a dictionary ����with the following keys: ����- 'question' the question to be passed to the retrieval chain ����- 'document' a base64 encoded document to be loaded into the vector database ����datarobot-user-models (DRUM) handles loading the model and calling ����this function with the appropriate parameters. ����Returns: ����-------- ����rv : str ��������Json dictionary with keys: ������������- 'question' user's original question ������������- 'answer' the generated answer to the question ����""" ����import json ����from langchain.chains import ConversationalRetrievalChain ����from langchain.document_loaders import PyPDFLoader ����from langchain.vectorstores.base import VectorStoreRetriever ����from langchain.vectorstores.faiss import FAISS ����llm, embedding_function = model ����DIRECTORY = "./storage/data" ����temp_file_name = "temp.PDF" ����data_dict = json.loads(data) ����# Write encoding to file ����base_64_to_file(data_dict['document'].encode(), filename=temp_file_name, directory_path=DIRECTORY) ����# Load up the file ����loader = PyPDFLoader(os.path.join(DIRECTORY, temp_file_name)) ����docs = loader.load_and_split() ����# Remove file when done ����os.remove(os.path.join(DIRECTORY, temp_file_name)) ����# Create our vector database� ����texts = [doc.page_content for doc in docs] ����metadatas = [doc.metadata for doc in docs]� ����db = FAISS.from_texts(texts, embedding_function, metadatas=metadatas)�� ����# Define our chain ����retriever = VectorStoreRetriever(vectorstore=db) ����chain = ConversationalRetrievalChain.from_llm( ��������llm,� ��������retriever=retriever ����) ����# Run it ����response = chain(inputs={'question': data_dict['question'], 'chat_history': []}) ����return json.dumps({"result": response}) ```With our hooks defined, all that�s left to do is deploy our pipeline so that we have an endpoint people can interact with. To some, the process of creating a secure, monitored and queryable endpoint out of arbitrary Python code may sound intimidating or at least time consuming to set up. Using the drx package, we can deploy our JITR Bot in one function call.
```python import datarobotx as drx deployment = drx.deploy( ����"./storage/deploy/", # Path with embedding model ����name=f"JITR Bot {now}",� ����hooks={ ��������"score_unstructured": score_unstructured, ��������"load_model": load_model ����}, ����extra_requirements=["pyPDF"], # Add a package for parsing PDF files ����environment_id="64c964448dd3f0c07f47d040", # GenAI Dropin Python environment ) ```How to Use JITR
Ok, the hard work is over. Now we get to enjoy interacting with our newfound deployment. Through Python, we can again take advantage of the drx package to answer our most pressing questions.
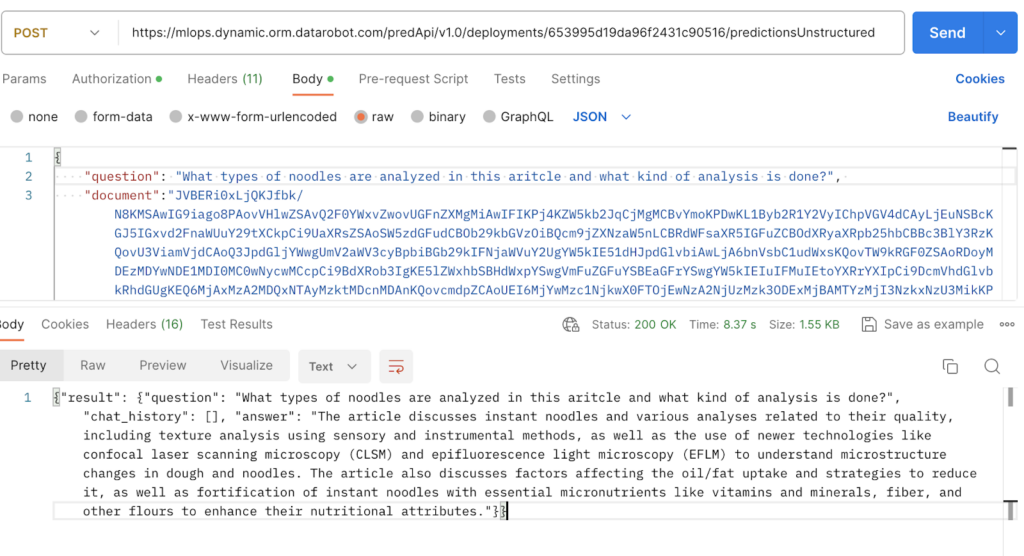
```python # Find a PDF url = "https://s3.amazonaws.com/datarobot_public_datasets/drx/Instantnoodles.PDF" resp = requests.get(url).content encoding = base64.b64encode(io.BytesIO(resp).read()) # encode it # Interact response = deployment.predict_unstructured( ����{ ��������"question": "What does this say about noodle rehydration?", ��������"document": encoding.decode(), ����} )['result'] � � � �� {'question': 'What does this say about noodle rehydration?', �'chat_history': [], �'answer': 'The article mentions that during the frying process, many tiny holes are created due to mass transfer, and they serve as channels for water penetration upon rehydration in hot water. The porous structure created during frying facilitates rehydration.'} ```But more importantly, we can hit our deployment in any language we want since it�s just an endpoint. Below, I show a screenshot of me interacting with the deployment right through Postman. This means we can integrate our JITR Bot into essentially any application we want by just having the application make an API call.
Once embedded in an application, using JITR is very easy. For example, in the Slackbot application used at DataRobot internally, users simply upload a PDF with a question to start a conversation related to the document.�
JITR makes it easy for anyone in an organization to start driving real-world value from generative AI, across countless touchpoints in employees� day-to-day workflows. Check out this video to learn more about JITR.�
Things You Can Do to Make the JITR Bot More Powerful
In the code I showed, we ran through a straightforward implementation of the JITRBot which takes an encoded PDF and makes a vector store at runtime in order to answer questions.� Since they weren�t relevant to the core concept, I opted to leave out a number of bells and whistles we implemented internally with the JITRBot such as:
Returning context aware prompt and completion tokens Answering questions based on multiple documents Answering multiple questions at once Letting users provide conversation history Using other chains for different types of questions Reporting custom metrics back to the deploymentThere�s also no reason why the JITRBot has to only work with PDF files! So long as a document can be encoded and converted back into a string of text, we could build more logic into our `score_unstructured` hook to handle any file type a user provides.
Start Leveraging JITR in Your Workflow
JITR makes it easy to interact with arbitrary PDFs. If you�d like to give it a try, you can follow along with the notebook here.
The post Deep Dive into JITR: The PDF Ingesting and Querying Generative AI Tool appeared first on DataRobot AI Platform.