


IntroductionIn the world of data science and machine learning, logistic regression is a powerful and widely-used algorithm. Despite its name, it has nothing to do with handling logistics or moving goods. Instead, it is a fundamental tool for classification...
Introduction
In the world of data science and machine learning, logistic regression is a powerful and widely-used algorithm. Despite its name, it has nothing to do with handling logistics or moving goods. Instead, it is a fundamental tool for classification tasks, helping us predict whether something belongs to one of two categories, like yes/no, true/false, or spam/not spam. In this blog, we will break down the concept of logistic regression and explain it as simply as possible.
What is Logistic Regression?
Logistic regression is a type of supervised learning algorithm. The term �regression� might be misleading, as it is not used for predicting continuous values like in linear regression. Instead, it deals with binary classification problems. In other words, it answers questions that can be answered with a simple �yes� or��no.�
Imagine you are an admissions officer at a university, and you want to predict whether a student will be admitted based on their test scores. Logistic regression can help you make that prediction!
The Sigmoid�Function
At the core of logistic regression lies the sigmoid function. It may sound complex, but it�s just a mathematical function that squashes any input to a value between 0 and�1.
The formula for the sigmoid function�is:
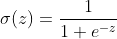 Equation 1. Sigmoid Function.
Equation 1. Sigmoid Function.Where:
z is the input to the function.Let�s visualize it:
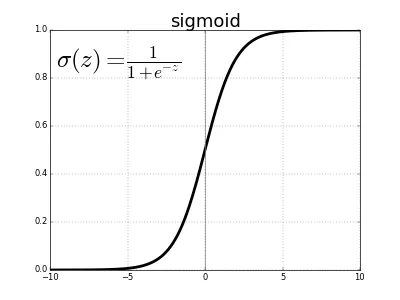 Figure 1. Sigmoid Function.
Figure 1. Sigmoid Function.As you can see, the sigmoid function maps large positive values of z close to 1 and large negative values close to 0. When z = 0, sigmoid(z) is exactly�0.5.
Making Predictions
Now, we understand the sigmoid function, but how does it help us make predictions?
In logistic regression, we assign a score to each data point, which is the result of a linear combination of the input features. Then, we pass this score through the sigmoid function to obtain a probability value between 0 and�1.
Mathematically, the score z is calculated as:
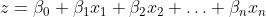
Where:
Betas (beta_0, beta_1, beta_2,���, beta_n) are coefficients (weights) that the algorithm learns from the training�data.beta_0 is commonly known as the bias�weight.X (x_1, x_2,���, x_n) are the input features of a data�point.Once we have the probability sigmoid(z), we can interpret it as the likelihood of the data point belonging to the positive class (e.g., admission).
Setting a Threshold
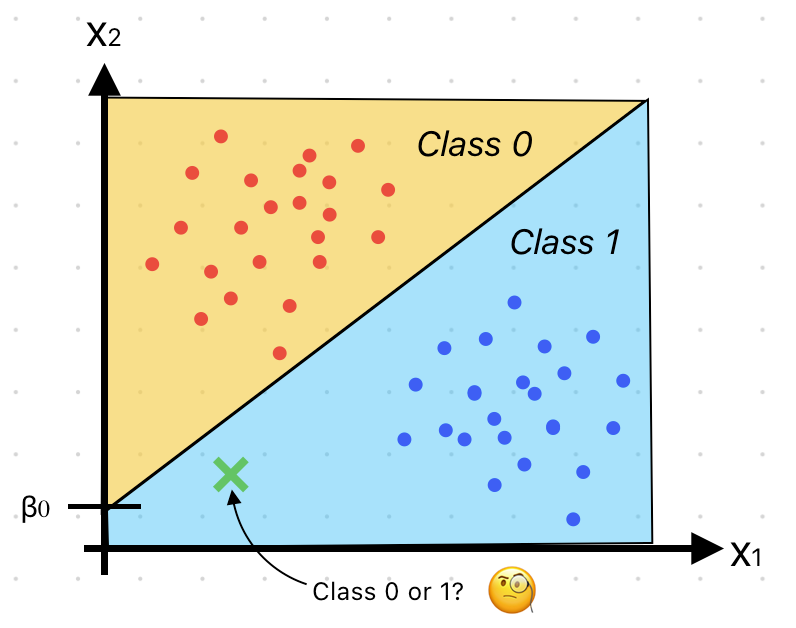
Since logistic regression gives us probabilities, we need to make a decision based on those probabilities. We do this by setting a threshold, usually at 0.5. If sigmoid(z) is greater than or equal to 0.5, we predict the positive class; otherwise, we predict the negative�class.
Conclusion
In summary, logistic regression is a simple but effective algorithm for binary classification problems. It uses the sigmoid function to map the scores to probabilities, making it easy to interpret the�results.
Remember, logistic regression is just one piece of the vast and exciting field of machine learning, but it�s a crucial building block in your data science journey. Happy classifying!
TLDR: Key Takeaways for the Logistic Regression Blog:
1. Logistic Regression for Binary Classification: Logistic regression is a powerful algorithm used for binary classification tasks. It helps predict whether something belongs to one of two categories, making it ideal for yes/no, true/false, or spam/not spam scenarios.
2. Sigmoid Function: At the heart of logistic regression lies the sigmoid function, which maps input values to probabilities between 0 and 1. This function is critical in converting the linear combination of input features into a probability score.
3. Probability Interpretation: Unlike other regression methods, logistic regression produces probabilities instead of continuous values. These probabilities represent the likelihood of a data point belonging to the positive class, allowing for a clear understanding of the model�s predictions.
4. Threshold Setting: To make actual predictions, a threshold is set (usually 0.5). If the predicted probability is greater than or equal to the threshold, the positive class is predicted; otherwise, the negative class is predicted. Adjusting the threshold can impact the model�s precision and recall trade-off.
5. Fundamental Building Block: Logistic regression is a fundamental concept in the world of machine learning and serves as a basis for more complex algorithms. Understanding logistic regression lays the groundwork for tackling more advanced classification problems and exploring a wider range of data science applications.
By grasping these key takeaways, you can appreciate the simplicity and significance of logistic regression in solving binary classification tasks and embark on your journey to explore the fascinating field of machine learning�further.
Thank you for reading and I hope this post is useful to you. Any comments or feedback is greatly appreciated.
My name is WeiQin Chuah (aka Wei by most of my colleagues) and I am a Research Fellow at RMIT University, Melbourne, Australia. My research focuses on developing robust deep learning models for solving computer vision problems. You can find more about me on my LinkedIn�page.
Demystifying Logistic Regression: A Simple Guide was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.







