The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on large language models (LLMs), reflecting current trends in AI research. The post Award-Winning Breakthroughs at NeurIPS 2023: A Focus on Language Model...
Generated with Midjourney
The NeurIPS 2023 conference showcased a range of significant advancements in AI, with a particular focus on large language models (LLMs), reflecting current trends in AI research. This year, the award committees recognized excellence in the field by granting two Outstanding Papers Awards and two Runner-up Awards. These awards highlight the latest achievements and novel approaches in AI research. Additionally, two Dataset Awards were given, acknowledging the importance of robust and diverse datasets in AI development. A Ten-Year Test-of-Time Award was also presented, marking the long-term impact and relevance of a research paper from a decade ago.
Let�s briefly review the key contributions of these research papers to understand their impact and the advancements they bring to the field.
Outstanding Papers Awards
Are Emerged Abilities of Large Language Models a Mirage?
By Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo from Stanford University
The paper challenges the notion of emergent abilities in large language models, which are believed to appear suddenly and unpredictably as the model scales. The authors argue that these abilities are not inherent to the models but are instead artifacts of the metrics used in research. They propose that nonlinear or discontinuous metrics can falsely suggest emergent abilities, whereas linear or continuous metrics show smooth, predictable changes in performance. The paper tests this hypothesis using the InstructGPT/GPT-3 models and a meta-analysis of emergent abilities in BIG-Bench, alongside experiments in vision tasks across various deep networks. The findings indicate that alleged emergent abilities might evaporate under different metrics or more robust statistical methods, suggesting that such abilities may not be fundamental properties of scaling AI models.
Privacy Auditing with One (1) Training Run
By Thomas Steinke, Milad Nasr, and Matthew Jagielski from Google
This research paper introduces a novel method for auditing differentially private (DP) machine learning systems using just a single training run. The approach is based on the concept of differential privacy and its relation to statistical generalization. The key innovation lies in analyzing the impact of adding or removing multiple independent data points in a single algorithm run, rather than relying on multiple runs. This method moves away from the traditional group privacy analysis, exploiting the parallelism of independent data points to achieve a more efficient auditing process.
The paper�s primary theoretical contribution is an improved analysis of the connection between differential privacy and statistical generalization, resulting in nearly tight bounds for the proposed auditing scheme. The approach is versatile, applicable in both black-box and white-box settings, and requires minimal assumptions about the algorithm being audited.
If this in-depth research-focused content is useful for you, subscribe to our AI mailing list to be alerted when we release new material.�
Runner-up Awards
Scaling Data-Constrained Language Models
By Niklas Muennighoff (Hugging Face), Alexander M. Rush (Hugging Face), Boaz Barak (Harvard University), Teven Le Scao (Hugging Face), Aleksandra Piktus (Hugging Face), Nouamane Tazi (Hugging Face), Sampo Pyysalo (University of Turku), Thomas Wolf (Hugging Face), and Colin Raffel (Hugging Face)
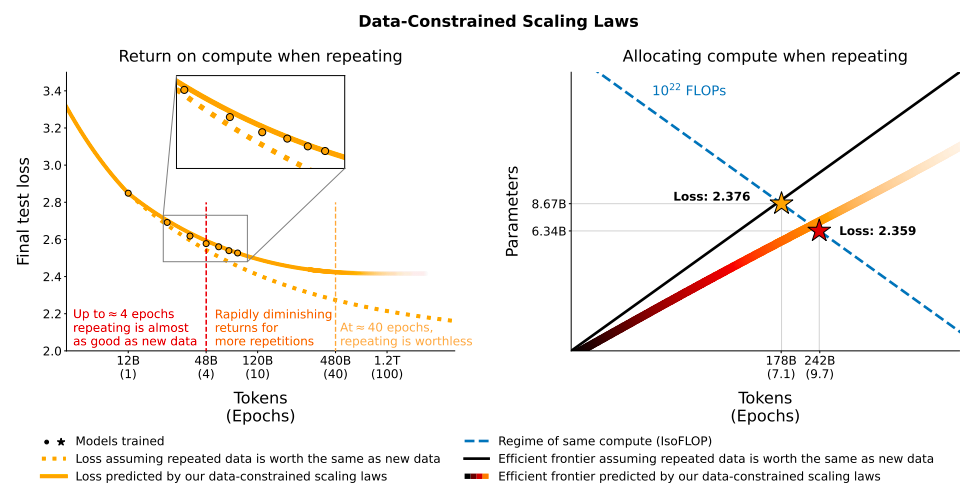
This paper explores the scaling of LLMs in situations where data is limited. The current trend in LLMs involves increasing both the number of parameters and the size of the training dataset. However, the finite amount of text data available on the internet presents a potential limit to this approach. The researchers address this challenge by conducting over 400 training runs of models ranging from 10 million to 9 billion parameters, trained for up to 1500 epochs, under various data and compute constraints.
A key finding is that for a fixed compute budget, training with up to four epochs of repeated data shows negligible differences in loss compared to training with unique data. However, beyond four epochs, the additional computational investment yields diminishing returns.
The paper also explores alternative strategies to mitigate data scarcity. This includes augmenting the training dataset with code data and reevaluating commonly used data filters. Interestingly, mixing natural language data with Python code data at varying rates showed that code data can effectively double the number of useful tokens for evaluating natural language tasks. Additionally, the study finds that commonly used data filtering strategies, like perplexity and deduplication filtering, are mainly beneficial for noisy datasets, but not that much for clean datasets.
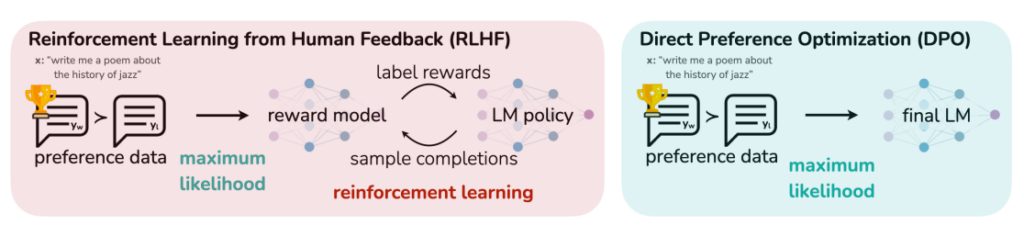
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
By Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn from Stanford University
The paper from Stanford University introduces Direct Preference Optimization (DPO), a novel approach to refining the behavior of large language models to align with human preferences. Traditionally, achieving precise control over LLMs is challenging due to their unsupervised training nature. The common method, Reinforcement Learning from Human Feedback (RLHF), involves a complex and unstable process of fitting a reward model to human preferences and then fine-tuning the LM using reinforcement learning.
DPO simplifies this process by reparameterizing the reward model in RLHF, allowing the extraction of the optimal policy directly and solving the RLHF problem with a simple classification loss. This method is stable, efficient, and computationally less demanding, eliminating the need for sampling from the LM during fine-tuning or extensive hyperparameter tuning.
The paper demonstrates that DPO can fine-tune LMs to align with human preferences as effectively, if not more so, than existing methods. Notably, DPO surpasses PPO-based RLHF in controlling the sentiment of generations and matches or improves response quality in tasks like summarization and single-turn dialogue.
Outstanding Datasets and Benchmarks Awards
ClimSim: A Large Multi-scale Dataset for Hybrid Physics-ML Climate Emulation
By Yu S. et al.
This research paper introduces ClimSim, a groundbreaking dataset designed to advance hybrid machine learning (ML) and physics-based approaches in climate modeling. Modern climate projections are often limited in spatial and temporal resolution due to computational constraints, leading to inaccuracies in predicting critical processes like storms. Hybrid methods, blending physics with ML, offer a solution by using ML emulators to perform compute-intensive, short, high-resolution simulations, thus bypassing the limitations imposed by Moore�s Law.
ClimSim stands out as the largest dataset ever created specifically for hybrid ML-physics research in climate simulation. It is a product of collaboration between climate scientists and ML researchers, featuring 5.7 billion pairs of multivariate input and output vectors. These vectors capture the impact of high-resolution, high-fidelity physics on the broader physical state of a host climate simulator.
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models
By Wang B. et al.�
The paper delves into the trustworthiness of Generative Pre-trained Transformer (GPT) models, particularly GPT-4 and GPT-3.5. Despite their advanced capabilities and growing use in sensitive areas like healthcare and finance, there�s a limited understanding of their trustworthiness. This study aims to fill that gap by providing a thorough evaluation of these models from various perspectives, including toxicity, stereotype bias, adversarial robustness, out-of-distribution robustness, privacy, machine ethics, and fairness.
The research reveals previously unidentified vulnerabilities in GPT models. It shows that these models can be easily manipulated to produce toxic and biased outputs and potentially leak private information from training data and conversation history. A notable finding is that while GPT-4 generally outperforms GPT-3.5 in standard benchmarks, it is more susceptible to being misled by specific prompts or jailbreaking techniques. This increased vulnerability is attributed to GPT-4�s higher precision in following instructions, which can be a double-edged sword.
The benchmark is publicly available through this webpage. Additionally, the dataset can be previewed at Hugging Face.
Ten-Year Test-of-Time Award
Distributed Representations of Words and Phrases and Their Compositionality
By Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, Jeffrey Dean from Google (at the time of paper release)
This paper, published 10 years ago, popularizes the ideas now considered standard parts of machine learning for NLP, in particular, continuous representations of words, concepts, and ideas. The research presented significant enhancements to the continuous Skip-gram model, an effective method for learning high-quality distributed vector representations of words that capture intricate syntactic and semantic relationships. The authors introduced several improvements that not only increased the quality of the vector representations but also accelerated the training process.
During their presentation at NeurIPS 2023, the authors defined the following key takeaways from this paper:
Semi-supervised objectives applied to large text corpora are the key to NLU. Fast, parallel, weakly-synchronized computation dominates in ML. The compute should be focused on the aspects of learning that need improvement. Tokenization can be used to solve seemingly nuanced problems. Treating language as a sequence of dense vectors is more powerful than expected.In conclusion, the award-winning papers from NeurIPS 2023, predominantly focusing on large language models, reflect a concerted effort in the AI community to deepen our understanding and enhance the capabilities of these powerful tools. From exploring the limits of data scaling and trustworthiness in language models to introducing innovative techniques for model optimization, these studies offer a multifaceted view of the current and future potential of AI.
Enjoy this article? Sign up for more AI research updates.
We�ll let you know when we release more summary articles like this one.
The post Award-Winning Breakthroughs at NeurIPS 2023: A Focus on Language Model Innovations appeared first on TOPBOTS.