The NeurIPS 2023 conference, held in the vibrant city of New Orleans from December 10th to 16th, had a particular emphasis on generative AI and large language models (LLMs). In light of the recent groundbreaking advancements in this domain,...
Generated with Midjourney
The NeurIPS 2023 conference, held in the vibrant city of New Orleans from December 10th to 16th, had a particular emphasis on generative AI and large language models (LLMs). In light of the recent groundbreaking advancements in this domain, it was no surprise that these topics dominated the discussions.
One of the core themes of this year�s conference was the quest for more efficient AI systems. Researchers and developers are actively seeking ways to construct AI that not only learns faster than current LLMs but also possesses enhanced reasoning capabilities while consuming fewer computing resources. This pursuit is crucial in the race towards achieving Artificial General Intelligence (AGI), a goal that seems increasingly attainable in the foreseeable future.
The invited talks at NeurIPS 2023 were a reflection of these dynamic and rapidly evolving interests. Presenters from various spheres of AI research shared their latest achievements, offering a window into cutting-edge AI developments. In this article, we delve into these talks, extracting and discussing the key takeaways and learnings, which are essential for understanding the current and future landscapes of AI innovation.
NextGenAI: The Delusion of Scaling and the Future of Generative AI�
In his talk, Bj�rn Ommer, Head of Computer Vision & Learning Group at Ludwig Maximilian University of Munich, shared how his lab came to develop Stable Diffusion, a few lessons they learned from this process, and the recent developments, including how we can blend diffusion models with flow matching, retrieval augmentation, and LoRA approximations, among others.
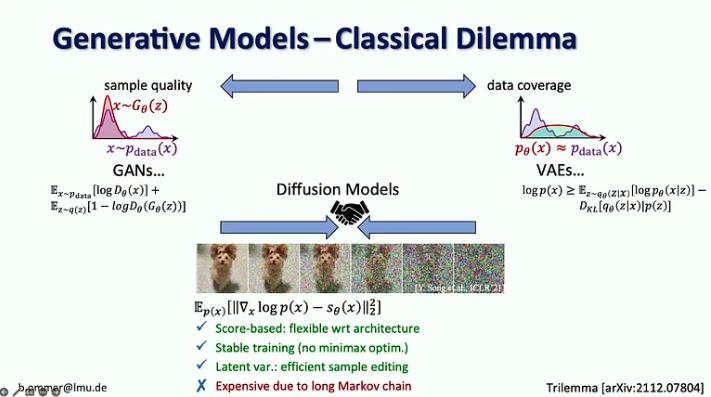
Key takeaways:
In the age of Generative AI, we moved from the focus on perception in vision models (i.e., object recognition) to predicting the missing parts (e.g., image and video generation with diffusion models). For 20 years, computer vision was focused on benchmark research, which helped to focus on the most prominent problems. In Generative AI, we don�t have any benchmarks to optimize for, which opened the field for everyone to go in their own direction. Diffusion models combine the advantages of previous generative models by being score-based with a stable training procedure and efficient sample editing, but they are expensive due to their long Markov chain. The challenge with strong likelihood models is that most of the bits go into details that are hardly perceptible by the human eye, while encoding semantics, which matters the most, takes only a few bits. Scaling alone wouldn�t solve this problem because demand for computing resources is growing 9x faster than GPU supply. The suggested solution is to combine the strengths of Diffusion models and ConvNets, particularly the efficiency of convolutions for representing local detail and the expressiveness of diffusion models for long-range context. Bj�rn Ommer also suggests using a flow-matching approach to enable high-resolution image synthesis from small latent diffusion models. Another approach to increasing the efficiency of image synthesis is to focus on scene composition while using retrieval augmentation to fill in the details. Finally, he introduced the iPoke approach for controlled stochastic video synthesis.If this in-depth content is useful for you, subscribe to our AI mailing list to be alerted when we release new material.�
?The Many Faces of Responsible AI�
In her presentation, Lora Aroyo, a Research Scientist at Google Research, highlighted a key limitation in traditional machine learning approaches: their reliance on binary categorizations of data as positive or negative examples. This oversimplification, she argued, overlooks the complex subjectivity inherent in real-world scenarios and content. Through various use cases, Aroyo demonstrated how content ambiguity and the natural variance in human viewpoints often lead to inevitable disagreements. She emphasized the importance of treating these disagreements as meaningful signals rather than mere noise.

Here are key takeaways from the talk:
Disagreement between human labers can be productive. Instead of treating all responses as either correct or wrong, Lora Aroyo introduced �truth by disagreement�, an approach of distributional truth for assessing reliability of data by harnessing rater disagreement. Data quality is difficult even with experts because experts disagree as much as crowd labers. These disagreements can be much more informative than responses from a single expert. In safety evaluation tasks, experts disagree on 40% of examples. Instead of trying to resolve these disagreements, we need to collect more such examples and use them to improve the models and evaluation metrics. Lora Aroyo also presented their Safety with Diversity method for scrutinizing the data in terms of what in it and who has annotated it. This method produced a benchmark dataset with variability in LLM safety judgments across various demographic groups of raters (2.5 million ratings in total). For 20% of conversations, it was difficult to decide whether the chatbot response was Safe or Unsafe, as there was a roughly equal number of respondents labeling them as either safe or unsafe. The diversity of raters and data plays a crucial role in evaluating models. Failing to acknowledge the wide range of human perspectives and the ambiguity present in content can hinder the alignment of machine learning performance with real-world expectations. 80% of AI safety efforts are already quite good, but the remaining 20% require doubling the effort to address edge cases and all the variants in the infinite space of diversity.?Coherence statistics, self-generated experience, and why young humans are much smarter than current AI�
In her talk, Linda Smith, a Distinguished Professor at Indiana University Bloomington, explored the topic of data sparsity in the learning processes of infants and young children. She specifically focused on object recognition and name learning, delving into how the statistics of self-generated experiences by infants offer potential solutions to the challenge of data sparsity.
Key takeaways:
By the age of three, children have developed the ability to be one-shot learners in various domains. In less than 16,000 waking hours leading up to their fourth birthday, they manage to learn over 1,000 object categories, master the syntax of their native language, and absorb the cultural and social nuances of their environment. Dr. Linda Smith and her team discovered three principles of human learning that allow children to capture so much from such sparse data: The learners control the input, moment to moment they are shaping and structuring the input. For example, during the first few months of their lives, babies tend to look more at objects with simple edges. Since babies continually evolve in their knowledge and capabilities, they follow a highly constrained curriculum. The data they are exposed to is organized in profoundly significant ways. For example, babies under 4 months spend the most time looking at faces, approximately 15 minutes per hour, whereas those older than 12 months focus primarily on hands, observing them for about 20 minutes per hour. Learning episodes consist of a series of interconnected experiences. Spatial and temporal correlations create coherence, which in turn facilitates the formation of lasting memories from one-time events. For instance, when presented with a random assortment of toys, children often focus on a few �favorite� toys. They engage with these toys using repetitive patterns, which aids in faster learning of the objects. Transient (working) memories persist longer than the sensory input. Properties that enhance the learning process include multimodality, associations, predictive relations, and activation of past memories. For rapid learning, you need an alliance between the mechanisms that generate the data and the mechanisms that learn.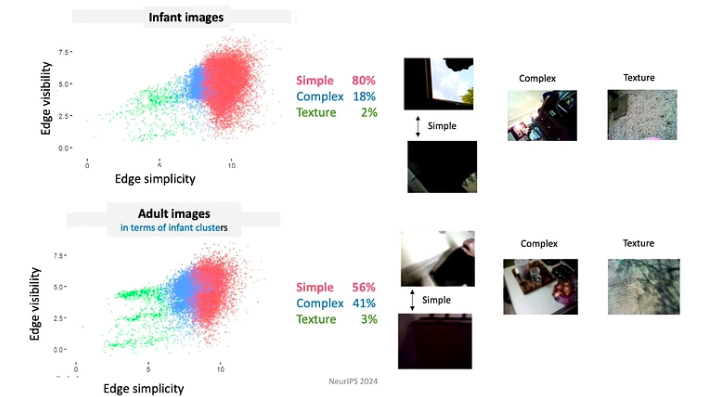
?Sketching: core tools, learning-augmentation, and adaptive robustness�
Jelani Nelson, a Professor of Electrical Engineering and Computer Sciences at UC Berkeley, introduced the concept of data �sketches� � a memory-compressed representation of a dataset that still enables the answering of useful queries. Although the talk was quite technical, it provided an excellent overview of some fundamental sketching tools, including recent advancements.
?Key takeaways:
CountSketch, the core sketching tool, was first introduced in 2002 to address the problem of �heavy hitters�, reporting a small list of the most frequent items from the given stream of items. CountSketch was the first known sublinear algorithm used for this purpose. Two non-streaming applications of heavy hitters include: Interior point-based method (IPM) that gives an asymptotically fastest known algorithm for linear programming. HyperAttention method that addresses the computational challenge posed by the growing complexity of long contexts used in LLMs. Much recent work has been focused on designing sketches that are robust to adaptive interaction. The main idea is to use insights from adaptive data analysis.Beyond Scaling Panel�
This great panel on large language models was moderated by Alexander Rush, an Associate Professor at Cornell Tech and a researcher at Hugging Face. The other participants included:
Aakanksha Chowdhery � Research Scientist at Google DeepMind with research interests in systems, LLM pretraining, and multimodality. She was part of the team developing PaLM, Gemini, and Pathways. Angela Fan � Research Scientist at Meta Generative AI with research interests in alignment, data centers, and multilinguality. She participated in the development of Llama-2 and Meta AI Assistant. Percy Liang � Professor at Stanford researching creators, open source, and generative agents. He is the Director of the Center for Research on Foundation Models (CRFM) at Stanford and the founder of Together AI.The discussion focused on four key topics: (1) architectures and engineering, (2) data and alignment, (3) evaluation and transparency, and (4) creators and contributors.
Here are some of the takeaways from this panel:
Training current language models is not inherently difficult. The main challenge in training a model like Llama-2-7b lies in the infrastructure requirements and the need to coordinate between multiple GPUs, data centers, etc. However, if the number of parameters is small enough to allow training on a single GPU, even an undergraduate can manage it. While autoregressive models are usually used for text generation and diffusion models for generating images and videos, there have been experiments with reversing these approaches. Specifically, in the Gemini project, an autoregressive model is utilized for image generation. There have also been explorations into using diffusion models for text generation, but these have not yet proven to be sufficiently effective. Given the limited availability of English-language data for training models, researchers are exploring alternative approaches. One possibility is training multimodal models on a combination of text, video, images, and audio, with the expectation that skills learned from these alternative modalities may transfer to text. Another option is the use of synthetic data. It�s important to note that synthetic data often blends into real data, but this integration is not random. Text published online typically undergoes human curation and editing, which might add additional value for model training. Open foundation models are frequently seen as beneficial for innovation but potentially harmful for AI safety, as they can be exploited by malicious actors. However, Dr. Percy Liang argues that open models also contribute positively to safety. He argues that by being accessible, they provide more researchers with opportunities to conduct AI safety research and to review the models for potential vulnerabilities. Today, annotating data demands significantly more expertise in the annotation domain compared to five years ago. However, if AI assistants perform as expected in the future, we will receive more valuable feedback data from users, reducing the reliance on extensive data from annotators.?Systems for Foundation Models, and Foundation Models for Systems�
In this talk, Christopher R�, an Associate Professor in the Department of Computer Science at Stanford University, shows how foundation models changed the systems we build. He also explores how to efficiently build foundation models, borrowing insights from database systems research, and discusses potentially more efficient architectures for foundation models than the Transformer.
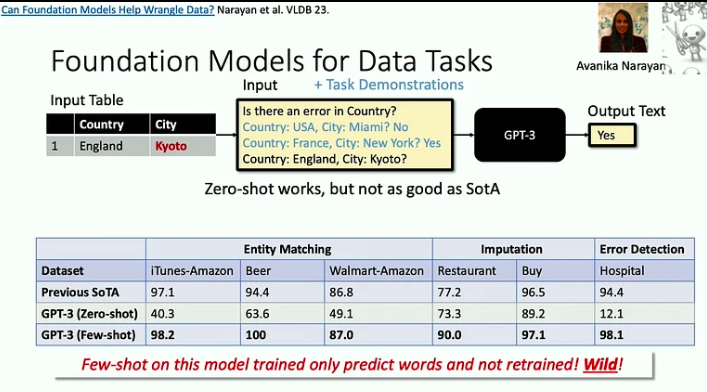
Here are the key takeaways from this talk:
Foundation models are effective in addressing �death by 1000 cuts� problems, where each individual task might be relatively simple, but the sheer breadth and variety of tasks present a significant challenge. A good example of this is the data cleaning problem, which LLMs can now help solve much more efficiently. As accelerators become faster, memory often emerges as a bottleneck. This is a problem that database researchers have been addressing for decades, and we can adopt some of their strategies. For instance, the Flash Attention approach minimizes input-output flows through blocking and aggressive fusion: whenever we access a piece of information, we perform as many operations on it as possible. There is a new class of architectures, rooted in signal processing, that could be more efficient than the Transformer model, especially at handling long sequences. Signal processing offers stability and efficiency, laying the foundation for innovative models like S4.Online Reinforcement Learning in Digital Health Interventions�
In her talk, Susan Murphy, Professor of Statistics and Computer Science at Harvard University, shared the first solutions to some of the challenges they face in developing online RL algorithms for use in digital health interventions.
Here are a few takeaways from the presentation:
Dr. Susan Murphy discussed two projects that she has been working on: HeartStep, where activities have been suggested based on data from smartphones and wearable trackers, and Oralytics for oral health coaching, where interventions were based on engagement data received from an electronic toothbrush. In developing a behavior policy for an AI agent, researchers must ensure that it is autonomous and can be feasibly implemented in the broader healthcare system. This entails ensuring that the time required for an individual�s engagement is reasonable, and that the recommended actions are both ethically sound and scientifically plausible. The primary challenges in developing an RL agent for digital health interventions include dealing with high noise levels, as people lead their lives and may not always be able to respond to messages, even if they wish to, as well as managing strong, delayed negative effects.As you can see, NeurIPS 2023 has provided an illuminating glimpse into the future of AI. The invited talks highlighted a trend towards more efficient, resource-conscious models and the exploration of novel architectures beyond traditional paradigms.
Enjoy this article? Sign up for more AI research updates.
We�ll let you know when we release more summary articles like this one.
The post NeurIPS 2023: Key Takeaways From Invited Talks appeared first on TOPBOTS.