In this article, we delve into ten transformative research papers from diverse domains, spanning language models, image processing, image generation, and video editing. The post Top 10 Influential AI Research Papers in 2023 from Google, Meta, Microsoft, and More...
From Generative Agents research paper
In this article, we delve into ten transformative research papers from diverse domains, spanning language models, image processing, image generation, and video editing. As discussions around Artificial General Intelligence (AGI) reveal that AGI seems more approachable than ever, it�s no wonder that some of the featured papers explore various paths to AGI, such as extending language models or harnessing reinforcement learning for domain-spanning mastery.
If you�d like to skip around, here are the research papers we featured:
Sparks of AGI by Microsoft PALM-E by Google LLaMA 2 by Meta AI LLaVA by University of Wisconsin�Madison, Microsoft, and Columbia University Generative Agents by Stanford University and Google Segment Anything by Meta AI DALL-E 3 by OpenAI ControlNet by Stanford University Gen-1 by Runway DreamerV3 by DeepMind and University of TorontoIf this in-depth educational content is useful for you, subscribe to our AI mailing list to be alerted when we release new material.�
Top 10 AI Research Papers 2023
1. Sparks of AGI by Microsoft
Summary
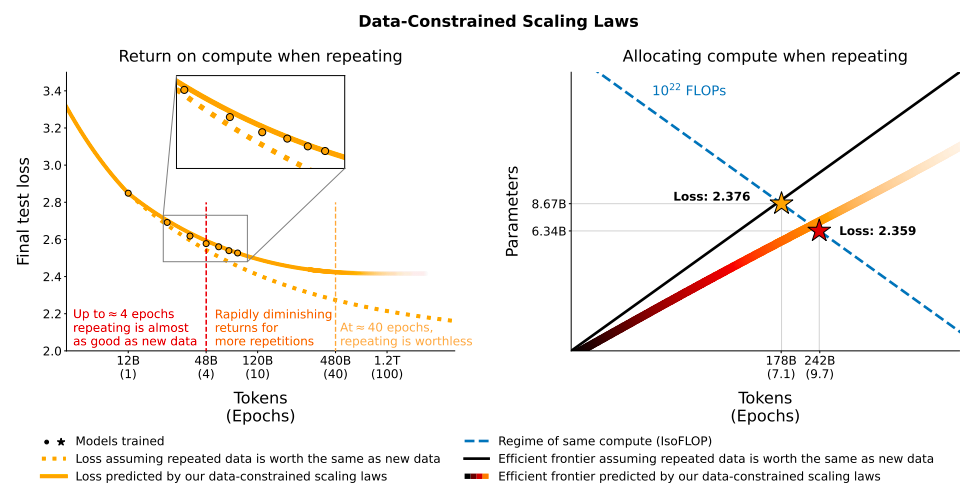
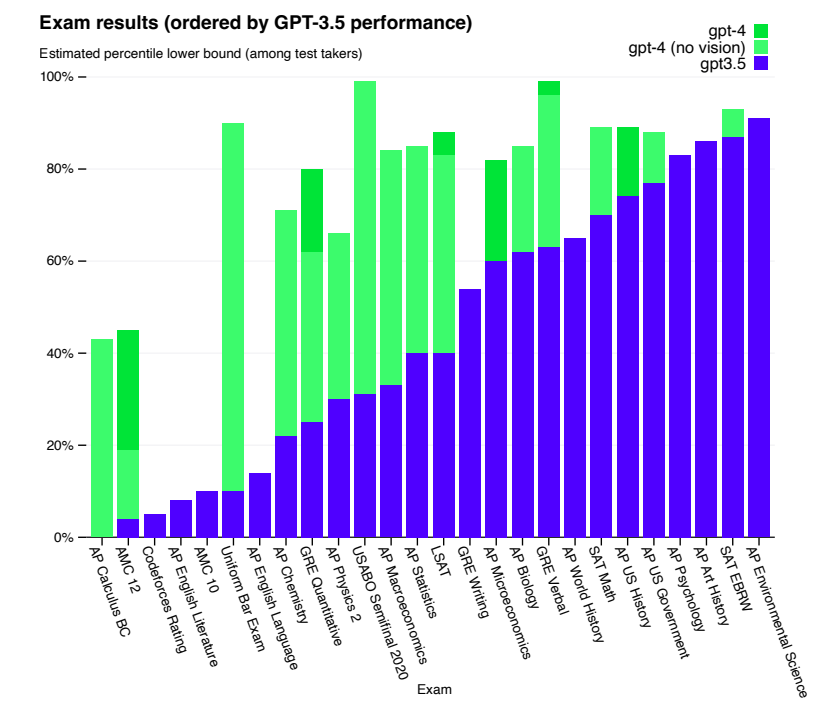
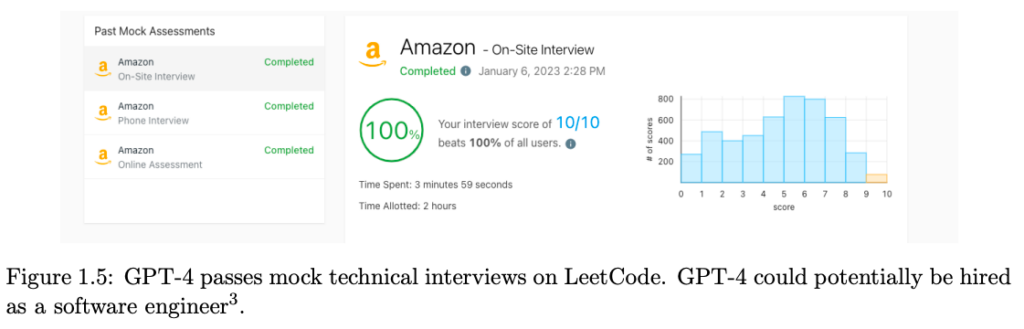
In this research paper, a team from Microsoft Research analyzes an early version of OpenAI�s GPT-4, which was still under active development at the time. The team argues that GPT-4 represents a new class of large language models, exhibiting more generalized intelligence compared to previous AI models. Their investigation reveals GPT-4�s expansive capabilities across various domains, including mathematics, coding, vision, medicine, law, and psychology. They highlight that GPT-4 can solve complex and novel tasks without specialized prompting, often achieving performance close to human level.�
The Microsoft team also emphasizes the potential of GPT-4 to be considered an early, albeit incomplete, form of artificial general intelligence (AGI). They focus on identifying GPT-4�s limitations and discuss the challenges in progressing towards more advanced and comprehensive AGI versions. This includes considering new paradigms beyond the current next-word prediction model.
Where to learn more about this research?
Sparks of Artificial General Intelligence: Early experiments with GPT-4 (research paper) Sparks of AGI: early experiments with GPT-4 (a talk by the paper�s first author S�bastien Bubeck)Where can you get implementation code?
Not applicable2. PALM-E by Google
Summary
The research paper introduces PaLM-E, a novel approach to language models that bridges the gap between words and percepts in the real world by directly incorporating continuous sensor inputs. This embodied language model seamlessly integrates multi-modal sentences containing visual, continuous state estimation, and textual information. These inputs are trained end-to-end with a pre-trained LLM and applied to various embodied tasks, including sequential robotic manipulation planning, visual question answering, and captioning.
PaLM-E, particularly the largest model with 562B parameters, demonstrates remarkable performance on a wide range of tasks and modalities. Notably, it excels in embodied reasoning tasks, exhibits positive transfer from joint training across language, vision, and visual-language domains, and showcases state-of-the-art capabilities in OK-VQA benchmarking. Despite its focus on embodied reasoning, PaLM-E-562B also exhibits an array of capabilities, including zero-shot multimodal chain-of-thought reasoning, few-shot prompting, OCR-free math reasoning, and multi-image reasoning, despite being trained on only single-image examples.
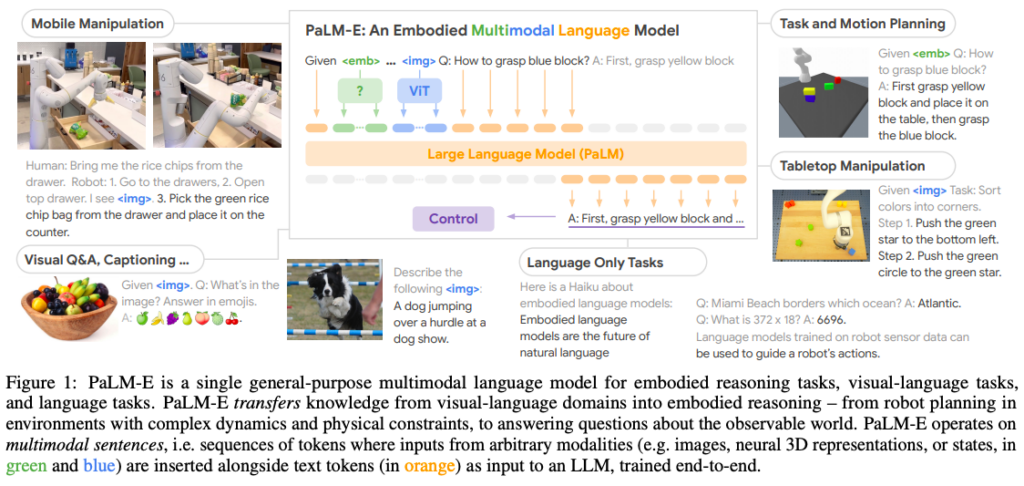
Where to learn more about this research?
PaLM-E: An Embodied Multimodal Language Model (research paper) PaLM-E (demos) PaLM-E (blog post)Where can you get implementation code?
Code implementation of the PaLM-E model is not available.3. LLaMA 2 by Meta AI
Summary�
LLaMA 2 is an enhanced version of its predecessor, trained on a new data mix, featuring a 40% larger pretraining corpus, doubled context length, and grouped-query attention. The LLaMA 2 series of models includes LLaMA 2 and LLaMA 2-Chat, optimized for dialogue, with sizes ranging from 7 to 70 billion parameters. These models exhibit superior performance in helpfulness and safety benchmarks compared to open-source counterparts and are comparable to some closed-source models. The development process involved rigorous safety measures, including safety-specific data annotation and red-teaming. The paper aims to contribute to the responsible development of LLMs by providing detailed descriptions of fine-tuning methodologies and safety improvements.
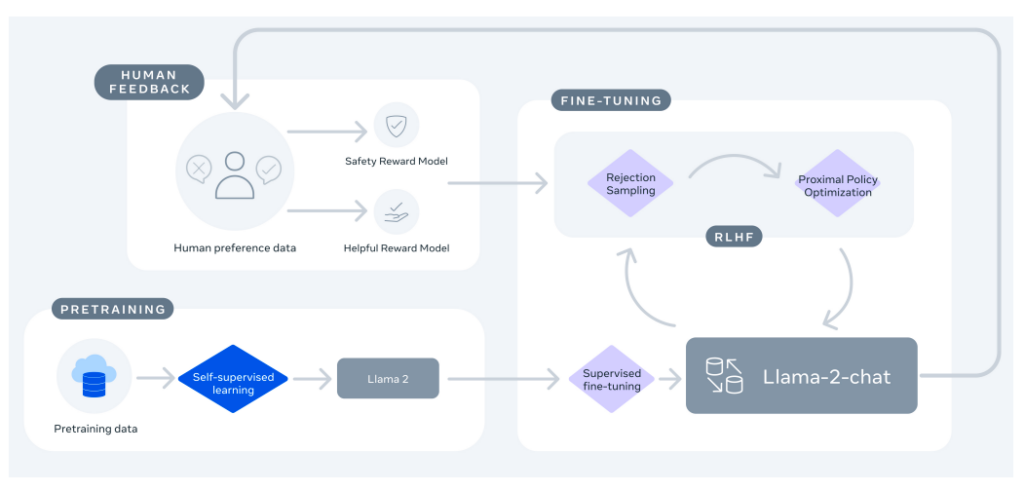
Where to learn more about this research?
Llama 2: Open Foundation and Fine-Tuned Chat Models (research paper) Llama 2: open source, free for research and commercial use (blog post)Where can you get implementation code?
Meta AI released LLaMA 2 models to individuals, creators, researchers, and businesses of all sizes. You can access model weights and starting code for pretrained and fine-tuned LLaMA 2 language models through GitHub.4. LLaVA by University of Wisconsin�Madison, Microsoft, and Columbia University
Summary
The research paper introduces LLaVA, Large Language and Vision Assistant, a groundbreaking multimodal model that leverages language-only GPT-4 to generate instruction-following data for both text and images. This novel approach extends the concept of instruction tuning to the multimodal space, enabling the development of a general-purpose visual assistant.
The paper addresses the challenge of a scarcity of vision-language instruction-following data by presenting a method to convert image-text pairs into the appropriate instruction-following format, utilizing GPT-4. They construct a large multimodal model (LMM) by integrating the open-set visual encoder of CLIP with the language decoder LLaMA. The fine-tuning process on generated instructional vision-language data proves effective, and practical insights are offered for building a general-purpose instruction-following visual agent.
The paper�s contributions include the generation of multimodal instruction-following data, the development of large multimodal models through end-to-end training on generated data, and the achievement of state-of-the-art performance on the Science QA multimodal reasoning dataset. Additionally, the paper demonstrates a commitment to open-source principles by making the generated multimodal instruction data, codebase for data generation and model training, model checkpoint, and a visual chat demo available to the public.
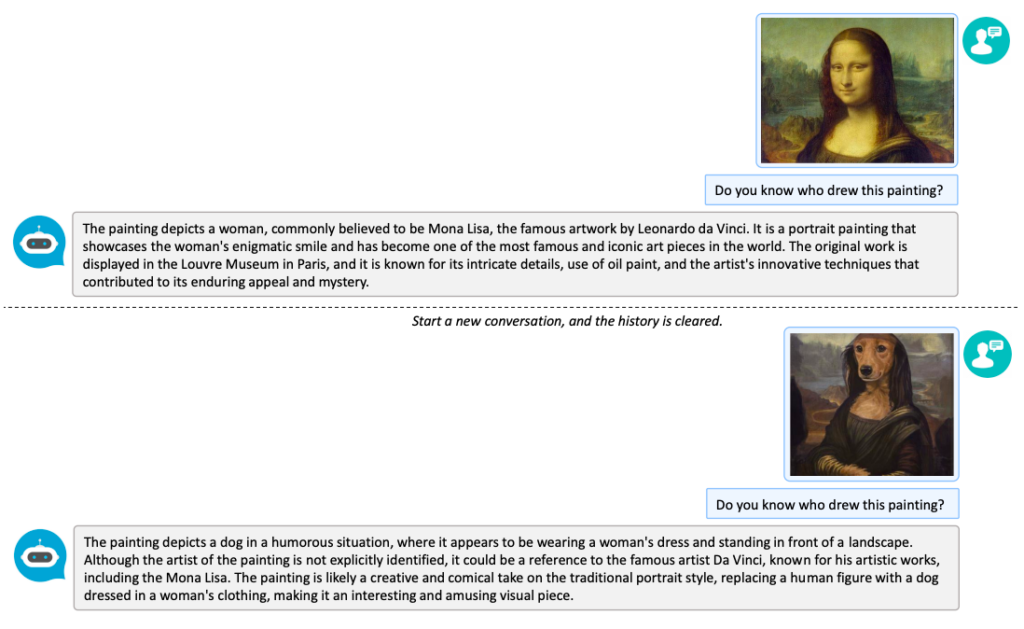
Where to learn more about this research?
Visual Instruction Tuning (research paper) LLaVA: Large Language and Vision Assistant (blog post with demos)Where can you get implementation code?
The LLaVa code implementation is available on GitHub.5. Generative Agents by Stanford University and Google
Summary
The paper introduces a groundbreaking concept � generative agents that can simulate believable human behavior. These agents exhibit a wide range of actions, from daily routines like cooking breakfast to creative endeavors such as painting and writing. They form opinions, engage in conversations, and remember past experiences, creating a vibrant simulation of human-like interactions.
To achieve this, the paper presents an architectural framework that extends large language models, allowing agents to store their experiences in natural language, synthesize memories over time, and retrieve them dynamically for behavior planning. These generative agents find applications in various domains, from role-play scenarios to social prototyping in virtual worlds. The research validates their effectiveness through evaluations, emphasizing the importance of memory, reflection, and planning in creating convincing agent behavior while addressing ethical and societal considerations.
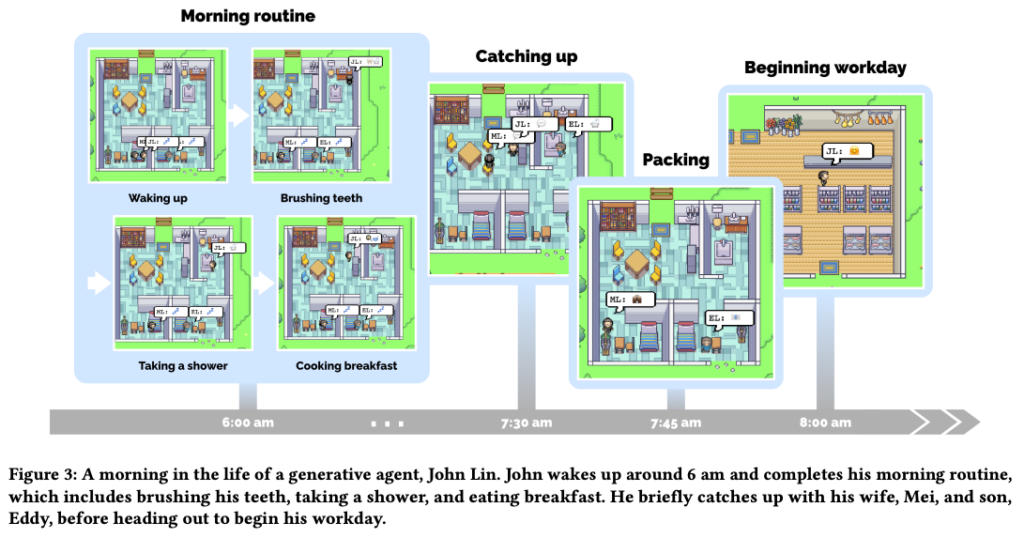
Where to learn more about this research?
Generative Agents: Interactive Simulacra of Human Behavior (research paper) Generative Agents (video presentation of the research by the paper�s first author, Joon Sung Park)Where can you get implementation code?
The core simulation module for generative agents was released on GitHub.6. Segment Anything by Meta AI
Summary
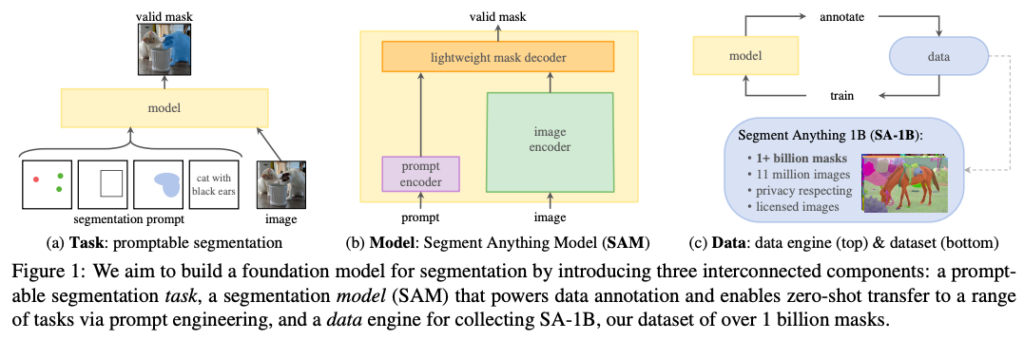
In this paper, the Meta AI team introduced a groundbreaking task, model, and dataset for image segmentation. Leveraging an efficient model in a data collection loop, the project has created the most extensive segmentation dataset to date, featuring over 1 billion masks for 11 million licensed and privacy-respecting images. To achieve their goal of building a foundational model for image segmentation, the project focuses on promptable models trained on a diverse dataset. SAM, the Segment Anything Model, employs a straightforward yet effective architecture comprising an image encoder, a prompt encoder, and a mask decoder. The experiments demonstrate that SAM competes favorably with fully supervised results on a diverse range of downstream tasks, including edge detection, object proposal generation, and instance segmentation.�
Where to learn more about this research?
Segment Anything (research paper) Segment Anything (the research website with demos, datasets, etc)Where can you get implementation code?
The Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images have been released here.7. DALL-E 3 by OpenAI
Summary
The research paper presents a groundbreaking approach to addressing one of the most significant challenges in text-to-image models: prompt following. Text-to-image models have historically struggled with accurately translating detailed image descriptions into visuals, often misinterpreting prompts or overlooking critical details. The authors of the paper hypothesize that these issues come from noisy and inaccurate image captions in the training dataset. To overcome this limitation, they developed a specialized image captioning system capable of generating highly descriptive and precise image captions. These enhanced captions are then used to recaption the training dataset for text-to-image models. The results are remarkable, with the DALL-E model trained on the improved dataset showcasing significantly enhanced prompt-following abilities.
Note: The paper does not cover training or implementation details of the DALL-E 3 model and only focuses on evaluating the improved prompt following of DALL-E 3 as a result of training on highly descriptive generated captions.

Where to learn more about this research?
Improving Image Generation with Better Captions (research paper) DALL-E 3 (blog post by OpenAI)Where can you get implementation code?
The code implementation of DALL-E 3 is not available, but the authors released text-to-image samples collected for the evaluations of DALL-E against the competitors.8. ControlNet by Stanford University
Summary
ControlNet is a neural network structure designed by the Stanford University research team to control pretrained large diffusion models and support additional input conditions. ControlNet learns task-specific conditions in an end-to-end manner and demonstrates robust learning even with small training datasets. The training process is as fast as fine-tuning a diffusion model and can be performed on personal devices or scaled to handle large amounts of data using powerful computation clusters. By augmenting large diffusion models like Stable Diffusion with ControlNets, the researchers enable conditional inputs such as edge maps, segmentation maps, and keypoints, thereby enriching methods to control large diffusion models and facilitating related applications.

Where to learn more about this research?
Adding Conditional Control to Text-to-Image Diffusion Models (research paper) Ablation Study: Why ControlNets use deep encoder? What if it was lighter? Or even an MLP? (blog post by ControlNet developers)Where can you get implementation code?
The official implementation of this paper is available on GitHub.9. Gen-1 by Runway
Summary
The Gen-1 research paper introduced a groundbreaking advancement in the realm of video editing through the fusion of text-guided generative diffusion models. While such models had previously revolutionized image creation and manipulation, extending their capabilities to video editing had remained a formidable challenge. Existing methods either required laborious re-training for each input or resorted to error-prone techniques to propagate image edits across frames. In response to these limitations, the researchers presented a structure and content-guided video diffusion model that allowed seamless video editing based on textual or visual descriptions of the desired output. The suggested solution was to leverage monocular depth estimates with varying levels of detail to gain precise control over structure and content fidelity.�
Gen-1 was trained jointly on images and videos, paving the way for versatile video editing capabilities. It empowered users with fine-grained control over output characteristics, enabling customization based on a few reference images. Extensive experiments demonstrated its prowess, from preserving temporal consistency to achieving user preferences in editing outcomes.

Where to learn more about this research?
Structure and Content-Guided Video Synthesis with Diffusion Models (research paper) Gen-1: The Next Step Forward for Generative AI (blog post by Runway) Gen-2: The Next Step Forward for Generative AI (blog post by Runway)Where can you get implementation code?
The code implementation of Gen-1 is not available.10. DreamerV3 by DeepMind and University of Toronto
Summary
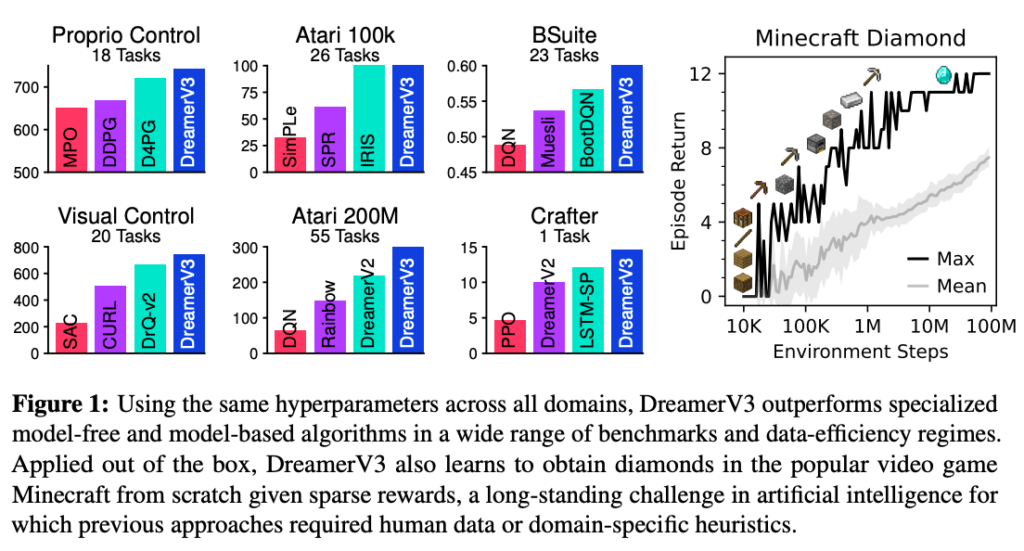
The paper introduces DreamerV3, a pioneering algorithm, based on world models, that showcases remarkable performance across a wide spectrum of domains, encompassing both continuous and discrete actions, visual and low-dimensional inputs, 2D and 3D environments, varied data budgets, reward frequencies, and reward scales. At the heart of DreamerV3 lies a world model that learns from experience, combining rich perception and imagination training. This model incorporates three neural networks: one for predicting future outcomes based on potential actions, another for assessing the value of different situations, and a third for learning how to navigate toward valuable situations. The algorithm�s generalizability across domains with fixed hyperparameters is achieved through the transformation of signal magnitudes and robust normalization techniques.�
A particularly noteworthy achievement of DreamerV3 is its ability to conquer the challenge of collecting diamonds in the popular video game Minecraft entirely from scratch, without any reliance on human data or curricula. DreamerV3 also demonstrates scalability, where larger models directly translate to higher data efficiency and superior final performance.
Where to learn more about this research?
Mastering Diverse Domains through World Models (research paper) DreamerV3 (project website)Where can you get implementation code?
A reimplementation of DreamerV3 is available on GitHub.In 2023, the landscape of AI research witnessed remarkable advancements, and these ten transformative papers have illuminated the path forward. From innovative language models to groundbreaking image generation and video editing techniques, these papers have pushed the boundaries of AI capabilities. As we reflect on these achievements, we anticipate even more transformative discoveries and applications on the horizon, shaping the AI landscape for years to come.
Enjoy this article? Sign up for more AI research updates.
We�ll let you know when we release more summary articles like this one.
The post Top 10 Influential AI Research Papers in 2023 from Google, Meta, Microsoft, and More appeared first on TOPBOTS.