Generative AI 3D Models. ReConFusion. LucidDreamer. DreaMo. HighFi4G. Mamba-chat. Apple MLX. Zephyr AIF. Pearl RL AI Agent. Schr�dinger Bridges
Generative AI 3D Models. I keep meeting colleagues in finance and insurance who are quite frustrated about the time, cost, and complexity involving the dev of production ready, enterprise RAG apps. Many of them tell me about their nightmarish MLOps scenarios of a RAG pipeline full of �unreliable/ inconsistent� dependencies like: LangChain, LlamaIndex, GPT Functions, embeddings, vector DBs/ search, external AI model APIs, hallucinations, fine-tuning, LoRA�
In the meantime, I meet people in media and marketing who are absolutely loving GenAI. Which brings me to Generative AI 3D models. Some amazing stuff happening in this area. Many of these GenAI 3D models combine methods like Gaussian splatting, diffusion models, Neural Radiance Fields (NeRF.) Here�s the latest on GenAI 3D models.
Real-world scenes reconstruction in 3D. Researchers at Google & Columbia Uni, just introduced ReConFusion: a new NeRF model that reconstructs real-world scenes from a few images. The model regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. ReconFusion beats previous NeRF models. Checkout paper and watch the video demos: ReconFusion: 3D Reconstruction with Diffusion Priors.

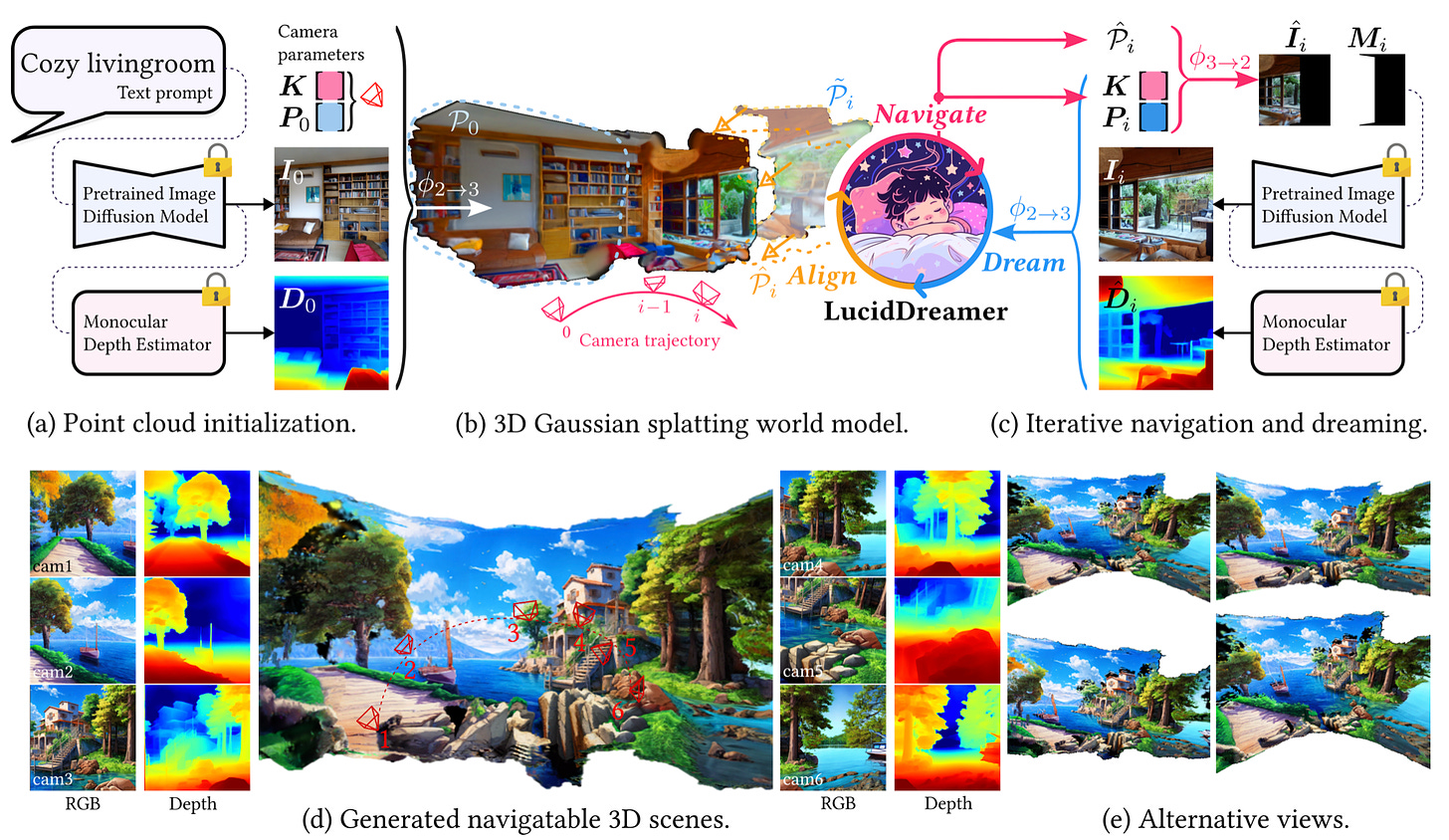
3D scenes generation without domain limitations. Until recently, 3D scene AI Gen models, limited the target scene to a specific domain, primarily due to their training strategies using 3D scan dataset. LucidDreamer is a new domain-free scene generation pipeline that fully leverages the power large-scale diffusion models. Checkout the paper, code and demos: LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes.
Articulated 3D reconstruction from one video. Existing methods for articulated 3D generation are expensive because they require a lot of work from domain experts, and template-free learning methods that use e.g. monocular video require full coverage of all viewpoints of the subject in the input video. DreaMo is a new Gen AI model that solves those issues. Checkout the paper and code: DreaMo: Articulated 3D Reconstruction From A Single Casual Video, and the demo video below.
Generation of photo-real human models. Efficiently rendering realistic photo-real human models and the required rasterisation pipeline is challenging and expensive. In this paper, a group of researchers just introduced HiFi4G, an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage. Checkout the paper and watch the awesome video demo: HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting.

Generating high quality, animated human avatars. Meta AI researchers just introduced Relightable Gaussian Codec Avatars, a method to build high-fidelity relightable head avatars that can be animated to generate novel expressions. The geometry model based on 3D Gaussians can capture 3D-consistent sub-millimeter face details of the avatar. The model can be efficiently relit in real-time under both point light and continuous illumination. Checkout the paper and watch the amazing demos: Relightable Gaussian Codec Avatars.

AI activities for the w/e. I love this collaborative, community game project: How (not) to get hit by a self-driving car. Can an AI detect you on the street? If you win you have a dilemma: either train the AI or not. Every player�s win generates vital data that exposes the inability of the AI to detect pedestrians and highlights the flaws of AI, which could potentially be used to improve self-driving cars in the future.
Have a nice week.
10 Link-o-Troned
The Irritating �Attention�, �Transformers�, in NNet �LLMs.�
The AI Battlefield Engineering - What You Need To Know
How to Create an AI Narrator for Your Life
Interactive: Visualising How LLMs Work
[free] Watch the 2nd Cerebral Valley AI Summit
Vertical AI: Key to Building Enduring AI Apps
An Intuitive Guide to Convolution
Building LLM Apps over Financial Data
Stanford WikiChat: Wikipedia + LLM (Almost Never Hallucinates)
Google How it�s Made: Interacting with Gemini & Multimodal Prompting
the ML Pythonista
Best Optimised Inference with NVIDIA & Hugging Face
Mamba-chat: 1st Chat LM NOT Based on a Transformer
Apple MLX: An Array Framework for ML, Transformers, Diffusion Models�
Deep & Other Learning Bits
How We Developed Llama 2 at Meta AI
Pearl - A Prod-ready RL AI Agent Library
A Review of Zephyr Model & Friends: AI Feedback (AIF) + DPO
AI/ DL ResearchDocs
Schr�dinger Bridges Beat Diffusion Models on Text-to-Speech
Google Research et al. - Visual Program Distillation (VPD)
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
data v-i-s-i-o-n-s
Embedding Visualisations of 7K NYT Articles
Psyc 6135: Psychology of Data Visualisation
An Animated Map Visualisation of Global Winds
MLOps Untangled
The MLOps Platform at Cloudflare
Our New, Git-Centric ML Versioning Framework
K8sGPT - Kubernetes Superpowers to Everyone in Plain English
AI startups -> radar
ASI - AI for Complex Air Operations
Mistral AI - Frontier AI in Your Hands
EnChargeAI - In-Mem AI Computing
ML Datasets & Stuff
The Llama Datasets Repo for RAG Apps
MAmmoTH - 13 Datasets for Math Generalist Models
Mozilla Common Voice: Open-source, Multi-language Voice Dataset
Postscript, etc
Tips? Suggestions? Feedback?�email Carlos
Curated by�@ds_ldn�in the middle of the night.