�Hi everyone,There are a ton of language models out there today! Many of which have their unique way of learning "self-supervised" language representations that can be used by other downstream tasks.�In this article, I decided to summarize the current...
�Hi everyone,
There are a ton of language models out there today! Many of which have their unique way of learning "self-supervised" language representations that can be used by other downstream tasks.�
In this article, I decided to summarize the current trends and share some key insights to glue all these novel approaches together.� ? (Slide credits: Delvin et. al. Stanford CS224n)
Problem: Context-free/Atomic Word Representations
We started with context-free approaches like word2vec, GloVE embeddings in my previous post. The drawback of these approaches is that they do not account for syntactic context. e.g. "open a bank account" v/s "on the river bank". The word bank has different meanings depending on the context the word is used in.
Solution #1: Contextual Word RepresentationsWith ELMo the community started building forward (left to right) and backward (right to left) sequence language models, and used embeddings extracted from both (concatenated) these models as pre-trained embeddings for downstream modeling tasks like classification (Sentiment etc.)
Potential drawback:
ELMo can be considered a "weakly bi-directional model" as they trained 2 separate models here.
Solution #2: Truly bi-directional Contextual Representations
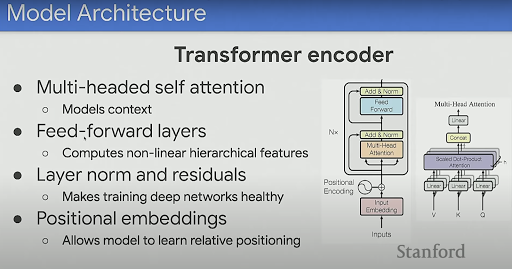
To solve the drawback of "weakly bi-directional" approach and the information bottleneck that comes with LSTMs / Recurrent approaches - the Transformer architecture was developed. Transformers unlike LSTM/RNN are an entirely feedforward network. Here is a quick summary of the architecture:
Tip: If you are new to transformers but are familiar with vanilla Multi-Layer Perceptron (MLP) or Fully connected Neural networks. You can think of transformers as being similar to MLP/standard NN with fancy bells and whistles on top of that.
But, what makes the transformer so much more effective?
2 key ideas:
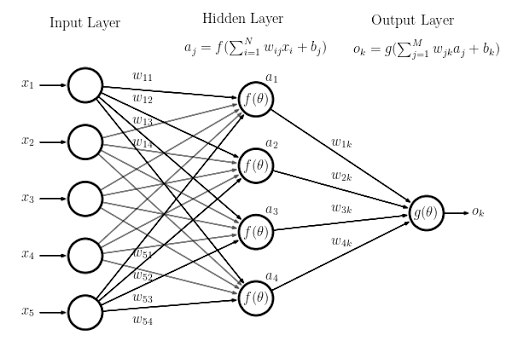
1. Every word has an opportunity to learn a representation with-respect-to every other word (Truly bi-directional)�in the sentence (think of every word as a feature given as input to a fully connected network). To further build on this idea let's consider the transformer as a fully connected network with 1 hidden layer as shown below:
If x1 and x5 are 2 words/tokens from my earlier example (on the river bank), now x1 has access to x5 regardless of the distance between x1 and x5 (the word on can learn a representation depending on the context provided by the word�bank)
2. Essentially, since every layer can be represented as a big matrix multiplication (parallel computation) over one multiplication per token that happens in an LSTM, the transformer is much faster than an LSTM.
Problem with bi-directional models:
But, Language models (LM) are supposed to model P(w_t+1/w_1..w_t)? How does the model learn anything if you expose all the words to it?
BERT develops upon this idea using transformers to learn Masked Language Modeling (MLM) and translates the task to P(w_masked/w_1..w-t)
Tradeoff: In MLM, you could be masking and predicting ~15% words in the sentence. However, in Left-to-Right LM you are predicting 100% of words in the sentence (higher sample efficiency).
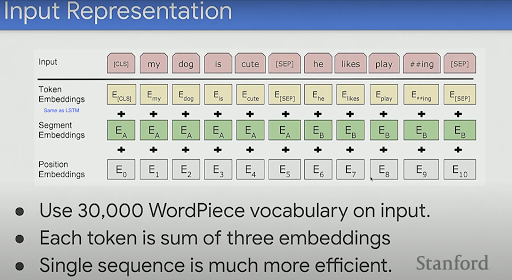
There are some changes in the input to the model with respect to the previous LSTM based approach. The input now has 3 embeddings:�
1. Token embeddings�- (Same as embeddings fed into the LSTM model)�
2. Segment Embeddings -�
Simply tells the model what sentence does this token belongs to e.g. "Sentence A: The man went to buy milk. Sentence B: The store was closed".
3. Position Embeddings -�
Can be thought as a token number e.g. The - 0, man - 1 and so on.
Important to note:
BERT is a huge model (110M parameters ~1 GB filesize). Alright, How do we do better?
Studies have shown that overly parameterized models are effective in learning language nuances better. This can be demonstrated by the graph below:
The graph affirms"Bigger the LM, the better it is" This is going to be some of our motivation as we look into advancements over the BERT model -
We will look into 4 models that have fundamentally improved upon the ideas we introduced for the BERT model.
1. RoBERTA
The central idea was to train the same BERT model for longer (more epochs) and on more data. The evaluation results show that it does better than the standard BERT model we saw earlier.
2. XLNet
XLNet introduced this idea of relative position embeddings instead of static position embeddings that we saw earlier. These start out as linear relationships and are combined together in deeper layers to learn a non-linear attention function.
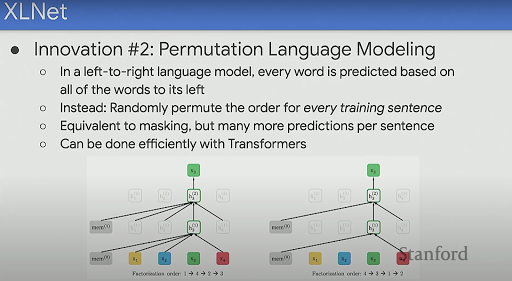
Additionally, instead of going just Left-to-Right, XLNet introduced this idea of Permutation Language Modelling (PLM) which allows us to randomly permute the order for every training sentence as shown in the figure. You are still predicting one "MASKED" word at a time given some permutation of the input. This gives us a much better sample efficiency.
3. ALBERT
The idea here was to reduce overfitting by factorizing the input embedding layer. As an example, if the vocab size is 100k and the hidden size is 1024. The model could have a hard time generalizing directly in this high dimensional vector space especially for rare words. Instead, ALBERT proposes a factorization technique which first learns a fairly small hidden dimension (128) per word and then learns to a separate function to project this to the transformers hidden dimension of 1024.�
To further reduce the number of parameters, ALBERT proposes to share all parameters between the transformers layers termed Cross-layer parameter sharing (All 12 layers of BERT share the same parameters). This comes at a cost of speed while training as shown in the table.
4. ELECTRA
ELECTRA introduces the idea of using a discriminator to be able to evaluate the quality of the generative language model. This helps the language model (generator) learn better language representations to help misguide the discriminator as an optimization objective.
I hope you enjoyed this post! Stay tuned for more. ?
Slide credits - Jacob Delvin, Google Language AI
https://www.youtube.com/watch?v=knTc-NQSjKA&ab_channel=stanfordonline
View Entire Post