


I decided to go through some of the break through papers in the field of NLP (Natural Language Processing) and summarize my learnings. The papers date from early 2000s to 2018. Source - KDNuggets If you are completely new...
I decided to go through some of the break through papers in the field of NLP (Natural Language Processing) and summarize my learnings. The papers date from early 2000s to 2018.
If you are completely new to the field of NLP - I recommend you start by reading this article which touches on a variety of NLP basics.
1. A Neural Probabilistic Language Model
2. Efficient Estimation of Word Representations in Vector Space
Word2Vec - Skipgram Model
3. Distributed Representations of Words and Phrases and their Compositionally
4.�GloVe: Global Vectors for Word Representation
5.�Recurrent neural network based language model�
6.�Extensions of Recurrent Neural Network Language Model
Let's start with #1,
The curse of dimensionality stems from using a vector representation of a single word equal to vocabulary size and learning the distance of one word with respect to all the words.
For example, to model a joint distribution of 10 consecutive words with a vocabulary size of 100,000 - The number of parameters to be learnt would be 1050-1.
A language can be statistically modeled to represent the conditional probability of the next word given all previous words from the corpus (within a window):
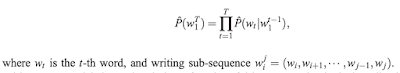


The basic learning objective here is two fold both of which happen in unison and reinforce each other:
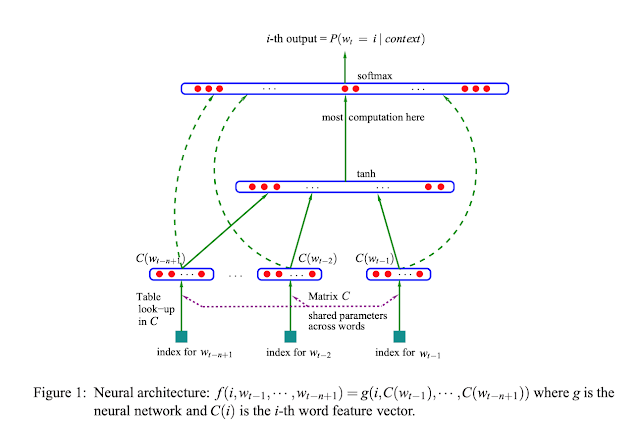
1. Learn a distributed representation C for the previous (context) words which signifies similarity. (linear projection)
2. Predict the correct next word given a window of previous words (window size is n for n-gram models -- non-linear hidden layer used to learn joint probabilities given context).
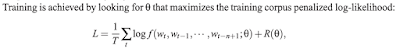
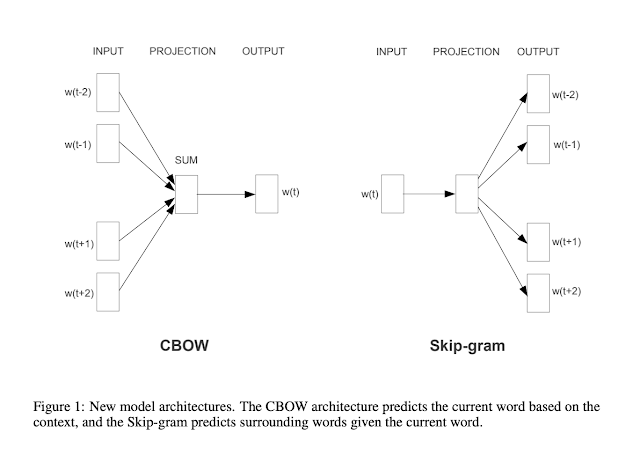
1. CBOW (Continuous Bag of Words Model)�
This is very similar to the NLM. However, the non-linear hidden layer is removed and the projection layer is shared by all words.� In comparison to NLM, we find the C (Projection Matrix) function which projects each of the context words and we average them together to find the target word (Shared is used in the sense that the vectors are Averaged). The orders of the words is not important in this approach. Similarity and scalability is given more importance.
2. Continuous Skip-gram Model
The architecture is the reverse of CBoW - given a target word, we predict the context words. Increasing the range (t+/-n) improves the quality of the word vectors but adds to the computational complexity.
The authors empirically show that both these models do better than NLM on syntactic and semantic tasks.
The idea of both the previous models is to learn quality word representations by doing a different task� (or sub-task) altogether - In case of Skip-gram it is to predict nearby words.


The objective of the Skip Gram model is to:
1. Maximize the conditional probability of prediction for the next word given all the previous words
2. Maximize the dot product (cosine distance) between the 2 vectors - the target vector w(t) at the input and the predicted (nearby) word vectors w(t+/-1) ...w(t+/-n).
Side note to help understand equation no 2,
The limitation of the Skip-Gram model emerges from equation no. 2 where we do this huge softmax for the entire vocabulary. This gives us a time complexity of O(|V|) where V is the size of the vocabulary.
In this paper, Pennington et. al. propose a technique which takes the best of both worlds -
1. Global Matrix Factorization (Global statistics of the text corpus)
2. Local Context Window Methods (Skip-gram, CBoW, Neural LM)
Methods like skip-gram do not utilize the global co-occurrence counts of words. The authors point out that simple models like Skip-Gram which use simple single-layer architecture based on dot product between two word vectors tend to do better than Neural network architectures. However, these local context window methods do not take advantage of the vast amounts of correlation between words when viewed as a whole corpus.

 Looking at Table 1: For words related to ice but not steam the ratio will be large (as seen for solid). However, for words related to steam but not ice, the ratio will be small. For words related to neither, the ratio will be close to 1. This tells us that global statistics of huge corpuses can influence "similarity".
Looking at Table 1: For words related to ice but not steam the ratio will be large (as seen for solid). However, for words related to steam but not ice, the ratio will be small. For words related to neither, the ratio will be close to 1. This tells us that global statistics of huge corpuses can influence "similarity".
The GloVE model performs all the way better than the improved Skip gram and CBoW model as shown in the results of this paper.
I would also like to briefly discuss a couple of papers about RNN based language models, these are more of an extension to the NNLM by Bengio et. all [1]. These may not be the best performing language models but provide great insight due to their short term conversational memory.

In this paper, the authors (Miklov et. al.) suggest further improvements to the previous RNN model accuracy with the concept of Back Propogation through Time (BTT). They also sight a few tricks to improve speedup and reduce the number of parameters. |
| Source - KDNuggets |
If you are completely new to the field of NLP - I recommend you start by reading this article which touches on a variety of NLP basics.
1. A Neural Probabilistic Language Model
2. Efficient Estimation of Word Representations in Vector Space
Word2Vec - Skipgram Model
3. Distributed Representations of Words and Phrases and their Compositionally
4.�GloVe: Global Vectors for Word Representation
5.�Recurrent neural network based language model�
6.�Extensions of Recurrent Neural Network Language Model
Let's start with #1,
A Neural Probabilistic Language Model
Bengio et al. propose a distributed representation for words to fight the curse of dimensionality.The curse of dimensionality stems from using a vector representation of a single word equal to vocabulary size and learning the distance of one word with respect to all the words.
For example, to model a joint distribution of 10 consecutive words with a vocabulary size of 100,000 - The number of parameters to be learnt would be 1050-1.
A language can be statistically modeled to represent the conditional probability of the next word given all previous words from the corpus (within a window):

The authors point out that most prior methods of language modeling suffer from the fact that they do not account for the "similarity" between words and focus on temporal locality.�

This helps learn semantic and grammatical similarity between words and helps generalize better.
To learn the joint probability function of word sequences the authors propose a Neural Network based approach:
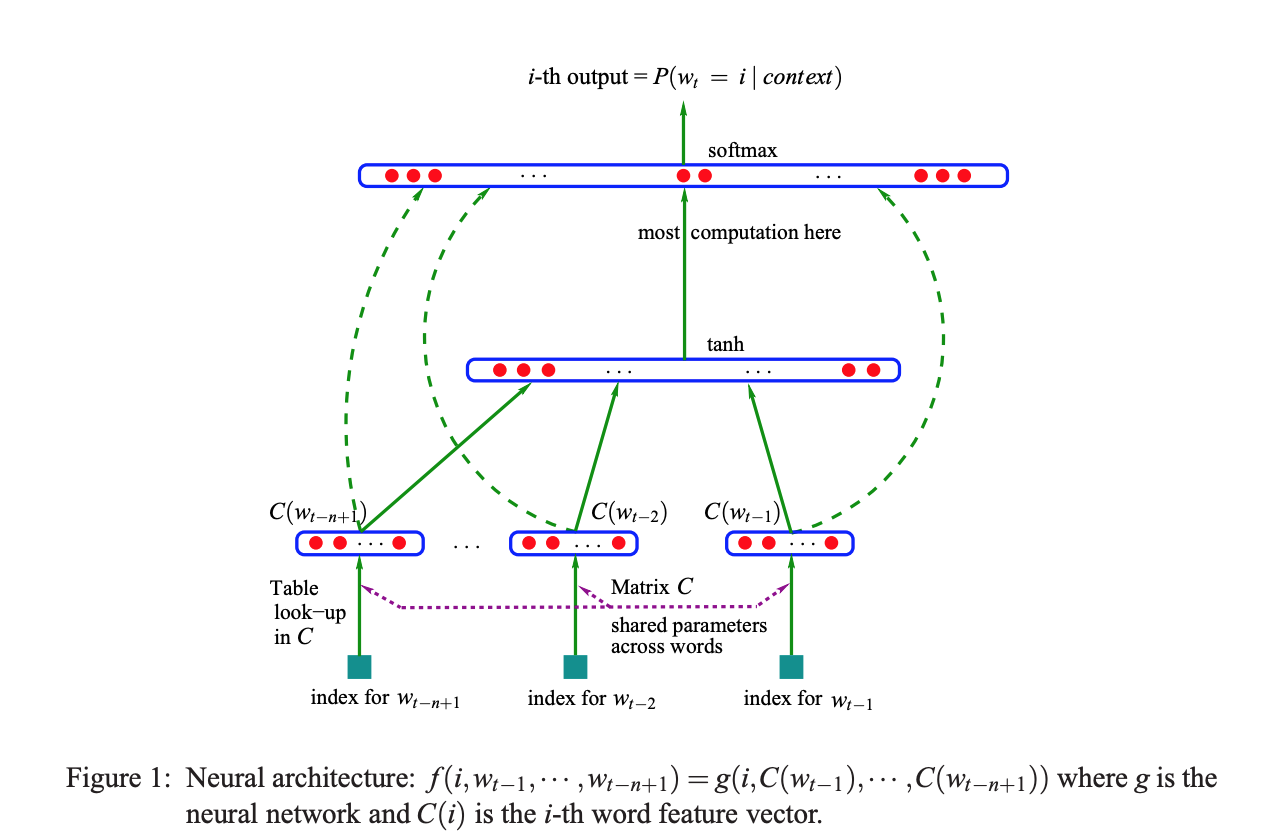
1. Learn a distributed representation C for the previous (context) words which signifies similarity. (linear projection)
2. Predict the correct next word given a window of previous words (window size is n for n-gram models -- non-linear hidden layer used to learn joint probabilities given context).

Note - the Loss is called "penalized" due to the presence of the regularization term. Also, the activation function used in this architecture is a tan hyperbolic non-linearity.
We will later learn that even non-linear models used for Language models tend to learn linear (or close to linear representations) implicitly.
The authors conclude by saying Neural Network based language models significantly outperform it's preceder - The N-Gram Model.
Efficient Estimation of Word Representations in Vector Space
The issue with the Neural network based model (NLM) is it's scalability on huge datasets comprising of billions of words. The authors - Mikolov et. al. try to address it with an alternative scheme.
Where the NLM tried to train the model on context/word similarity. The authors in this paper point out that words can have multiple degrees of similarity and word vectors can be used to express this.�
For example --
vector("King") - vector("Man") + vector("Woman") gets you closest to vector("Queen").
Language models can learn implicit meanings like gender and semantic relationships between them.
The limitation of NLMs is the fixed context window size, this limitation can be addressed by using a Recurrent Neural Network for Language Modelling (RNNLM). They also exhibit a form of short term memory which can be used to selectively remember/forget sequences which may be important for a later prediction.
The observations presented by the authors is that most of the complexity in these models are caused by the non-linear hidden layer activations. The authors propose 2 architectures:

1. CBOW (Continuous Bag of Words Model)�
This is very similar to the NLM. However, the non-linear hidden layer is removed and the projection layer is shared by all words.� In comparison to NLM, we find the C (Projection Matrix) function which projects each of the context words and we average them together to find the target word (Shared is used in the sense that the vectors are Averaged). The orders of the words is not important in this approach. Similarity and scalability is given more importance.
2. Continuous Skip-gram Model
The architecture is the reverse of CBoW - given a target word, we predict the context words. Increasing the range (t+/-n) improves the quality of the word vectors but adds to the computational complexity.
The authors empirically show that both these models do better than NLM on syntactic and semantic tasks.
Distributed Representations of Words and Phrases and their Compositionally
This is a follow up paper by Mikolov et. al. which proposes techniques to improve the CBoW and the Skip-Gram model presented in the last paper.The idea of both the previous models is to learn quality word representations by doing a different task� (or sub-task) altogether - In case of Skip-gram it is to predict nearby words.


The objective of the Skip Gram model is to:
1. Maximize the conditional probability of prediction for the next word given all the previous words
2. Maximize the dot product (cosine distance) between the 2 vectors - the target vector w(t) at the input and the predicted (nearby) word vectors w(t+/-1) ...w(t+/-n).
Side note to help understand equation no 2,
 |
Source - Stack Exchange |
The authors propose using Hierarchical Softmax which reduces the time complexity to log(|V|) as it represents the softmax in a binary tree based approach.�
Further, the authors discuss another technique called Negative Sampling which is inspired by Noise Contrastive Estimation (NCE). This is a way of increasing the distance between uncorrelated words explicitly.
Another interesting technique presented in the paper is Subsampling of Frequent Words. The idea is to selectively train the network which words which are less frequent. For example, training the network with word pairs like "the" and any noun does not really help the network learn anything. The idea is to form pairs of unique and less frequent words which help learn embedded similarities like "Pairs" and "France" (Target and context or interchangeably).
Subsampling improves accuracy and training speed significantly.
All these techniques preserve the linear additive nature of the vectors learnt by Skip-Gram and at the same time improve scalability and accuracy.
GloVe: Global Vectors for Word Representation
All the previous models discussed consider the immediate context (nearby words) for predicting target or context.In this paper, Pennington et. al. propose a technique which takes the best of both worlds -
1. Global Matrix Factorization (Global statistics of the text corpus)
2. Local Context Window Methods (Skip-gram, CBoW, Neural LM)
Methods like skip-gram do not utilize the global co-occurrence counts of words. The authors point out that simple models like Skip-Gram which use simple single-layer architecture based on dot product between two word vectors tend to do better than Neural network architectures. However, these local context window methods do not take advantage of the vast amounts of correlation between words when viewed as a whole corpus.

To explain this table better, let's look at the notation presented:

The GloVE model performs all the way better than the improved Skip gram and CBoW model as shown in the results of this paper.
I would also like to briefly discuss a couple of papers about RNN based language models, these are more of an extension to the NNLM by Bengio et. all [1]. These may not be the best performing language models but provide great insight due to their short term conversational memory.
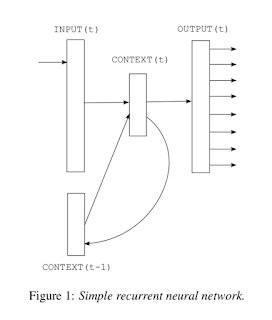
Recurrent neural network based language model (RNNLM)
Referring�back to the goal we started off with, Language�models need to be able to predict sequentially next words.�

The main advantage of using RNNLM is that they have their own hidden state / context similar to short term memory. By using Recurrent networks, information can cycle inside the network for arbitrary�long time (as learnt by the network) and is not limited by a window.

1. The current input to the network is the word at current time w(t) and the memory/hidden activation from the previous timesteps s(t-1) (This encompasses context information).
2. The RNN uses 2 different non-linearities, The first being the sigmoid to encompass the information for the context/hidden state.
2. Softmax to provide a probabilistic output for the next word. This is a V way softmax.
The authors also discuss using Dynamic training during testing which helps the network learn the use of memory for testing better and provides dynamic results on the fly.
An extension paper to this is another paper by Miklov et. al. called:
Extensions of Recurrent Network Neural Language Model
I encourage you to give these papers a read and post in the comments if you have questions :)
Please let me know if I have missed any other important papers here.
Thank you,
Ankit











