


Inside GPT?—?II : The Core Mechanics of Prompt EngineeringThe simple reasoning behind prompt engineeringDecrypting & Depicting Enigma Mashine (created through midjourney)Large language models are the compression of the world through the lens of human text*. In this blog post, we...
Inside GPT?—?II : The Core Mechanics of Prompt Engineering
The simple reasoning behind prompt engineering
 Decrypting & Depicting Enigma Mashine (created through midjourney)
Decrypting & Depicting Enigma Mashine (created through midjourney)Large language models are the compression of the world through the lens of human text*. In this blog post, we will examine the ways we can decode this compression and manipulate it’s output.
Having de-fractured GPT model architecture in Part I, let’s explore the ways we can influence the output of an already trained model.
During model training, our model learns about the world through human text projection. After training, each time when we prompt the model and generate text(inference), it forms a probability distribution involving every token in its vocabulary through the parameters it learned during the training.
Predicted token at a time becomes a last token of the input. Appended input with last predicted token is then used to predict the next token. So the text generation simply put, is a probability expression of the next token prediction given the tokens appear in the input(prompt).
What forms this probability? The model training. The text data that the model had seen during training process.
Let’s examine an example prompt sentence and make our explanation above less ambiguous:
“Germany is known for its”
How can you complete this sentence? You have learned what “Germany” is and you hold a conception based on what you have seen/heard/read (training data) throughout your life. Similar to a model when it is in its training phase. We collect large text data from internet/books. Then we filter and remove the harmful content. Through the model training eventually our model understands the world through the lens of human text.
So what is the next token that has the highest probability to complete our sentence? Lets look at GPT-2 to get the real probabilities by the model.
Input: "Germany is known for its"NEXT TOKEN:
Choice rank, token (probability)
Choice 1, high (3.30%)
Choice 2, strong (2.28%)
Choice 3, liberal (1.18%)
Choice 4, love (1.14%)
Choice 5, beautiful (0.96%)
Choice 6, generous (0.79%)
Choice 7, history (0.76%)
Choice 8," "" (0.75%)"
Choice 9, open (0.74%)
Choice 10, great (0.72%)
Choice 11, rich (0.67%)
Choice 12, beer (0.64%)
Choice 13, low (0.63%)
Choice 14, strict (0.61%)
Choice 15, unique (0.56%)
Choice 16, long (0.55%)
Choice 17, innovative (0.55%)
Choice 18, quality (0.55%)
Choice 19, many (0.52%)
Choice 20, large (0.50%)
Choice 21, heavy (0.50%)
.
.
.
Choice 89, harsh (0.17%)
Choice 90, wide (0.17%)
Choice 91, colorful (0.17%)
Choice 92, historic (0.17%)
Choice 93, ability (0.16%)
Choice 94, lack (0.16%)
Choice 95, aggressive (0.16%)
Choice 96, military (0.16%)
Choice 97, small (0.16%)
Choice 98, state (0.16%)
Choice 99, legendary (0.16%)
Choice 100, powerful (0.16%)
.
.
.
Choice 50158 phis (0.00000001097%)
Choice 50159 Florida (0.00000001094%)
Choice 50160 rez (0.00000001088%)
Choice 50161 etus (0.00000001066%)
Choice 50162 chapter (0.00000001045%)
Choice 50163 obin (0.00000001023%)
Choice 50164 Hong (0.00000000928%)
Choice 50165 assetsadobe (0.00000000894%)
Choice 50166 teasp (0.00000000862%)
Choice 50167 earthqu (0.00000000716%)
.
.
Choice 50255 ? (0.0000000000000774%)
Choice 50256 ???? (0.0000000000000749%)
Choice 50257 (0.0000000000000743%)
(Note: examples in this article are generated using GPT-2 model as it is a public model and small enough to illustrate the concepts through real examples.)
Above lays the probability distribution of the model given the prompt. For every token in the corpus (the text dataset that the model is trained on) we have a corresponding calculated probability. The total number of vocabulary of the model(which is 50,257 in GPT-2), is also the size of the probability distribution. The techniques behind the calculation of these probabilities were explained in detail, in the first article of this blog post series. (link)
The output you can generate from the pre-trained language model can be controlled through several decoding strategies. So whether we are trying to extract factual information or generate creative stories, we can impact the output and tune its factuality and creativity.
The simplest way to decode the predicted probabilities of the generated text is to simply get the token that has the highest probability at each prediction step.
Let’s extract the first five tokens with the highest predicted probabilities given our initial input sentence(prompt). Each predicted token becomes the last token of the input sentence until we reach the maximum token limit which is a parameter we define. In this example, let’s generate the next 10 tokens.
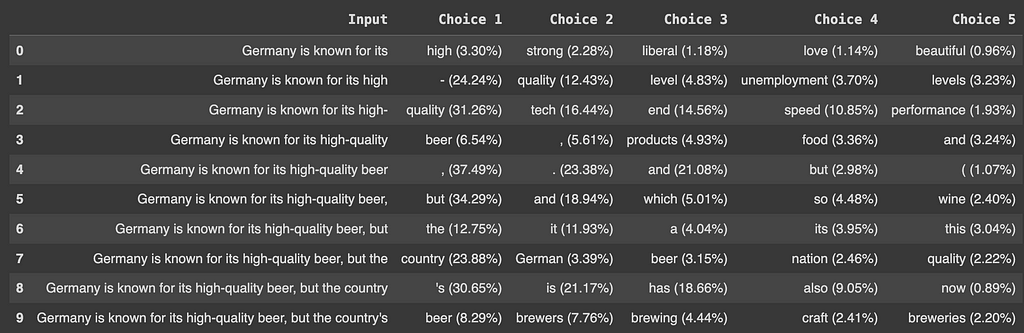 First 5 choice by probability (image by the author)
First 5 choice by probability (image by the author)As you can see above with greedy strategy, we append the token with the highest probability to the input sequence and predict the next token.
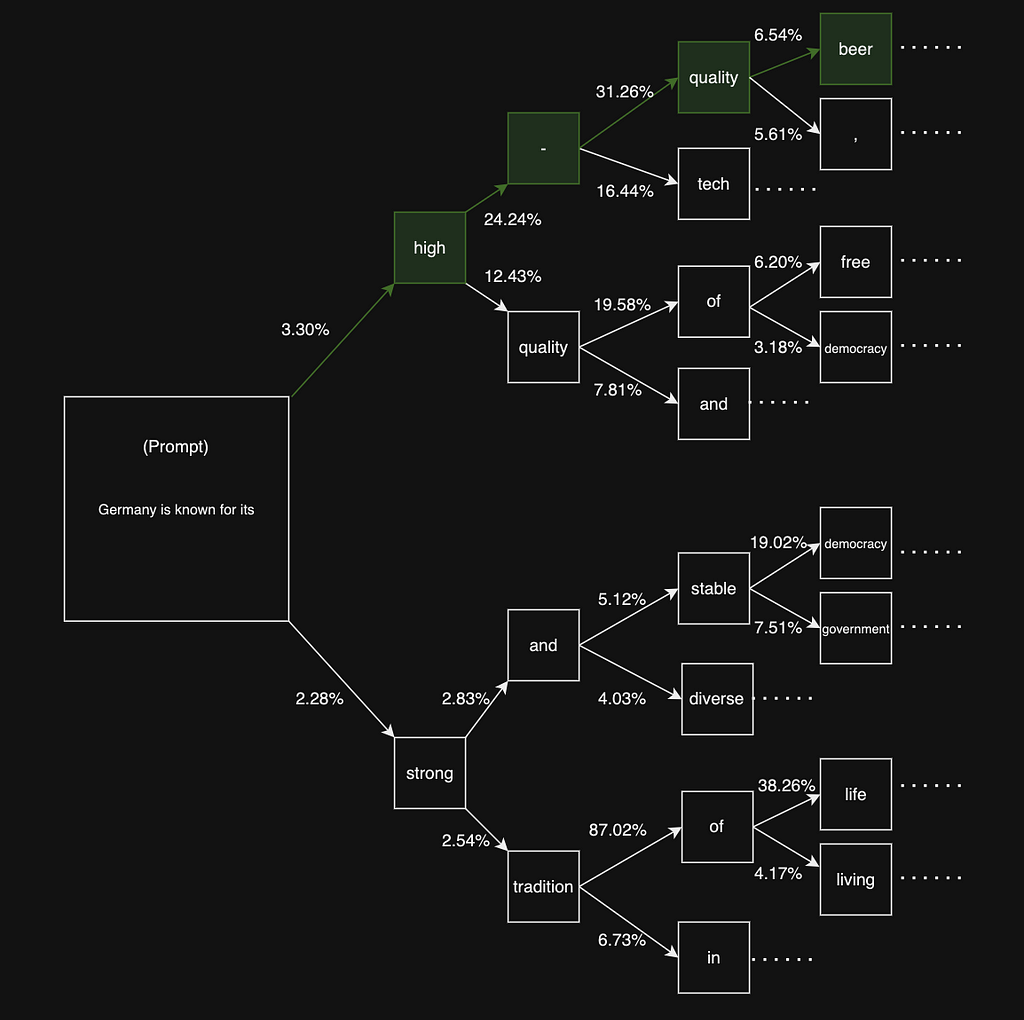 greedy search decision path (image by the author)
greedy search decision path (image by the author)Using this strategy let’s generate a longer text with 128 next tokens using greedy-search decoding.
"""Germany is known for its high-quality beer, but the country's beer culture is also a reflection of its history.
The country's beer culture is a reflection of its history. Beer is a German tradition.
The country's beer culture is a reflection of its history. Beer is a German tradition.
The country's beer culture is a reflection of its history. Beer is a German tradition.
The country's beer culture is a reflection of its history. Beer is a German tradition.
The
"""
As you we can see from the text above, although it is the simplest logic, the drawback of this approach is the generated repetitive sequences. As it fails to capture the probabilities of sequences, meaning, the overall probability of a several words coming one after another is overlooked. Greedy search predicts and considers only the probability one step at a time.
Repetitive text is a problem. We would desire our generated output to be concise, how can we achieve it?
Instead of choosing the token that has highest probability at each step, we consider future x-steps and calculate the joint probability(simply multiplication of consecutive probabilities) and choose the next token sequence that is most probable. While x refers to number of beams, it is the depth of the future sequence we look into the future steps. This strategy is known as the beam search.
Let’s go back to our example from GPT-2 and explore beam vs greedy search scenarios.
Given the prompt, looking at the two tokens with highest probability and their continuation(4 beams) in a tree diagram
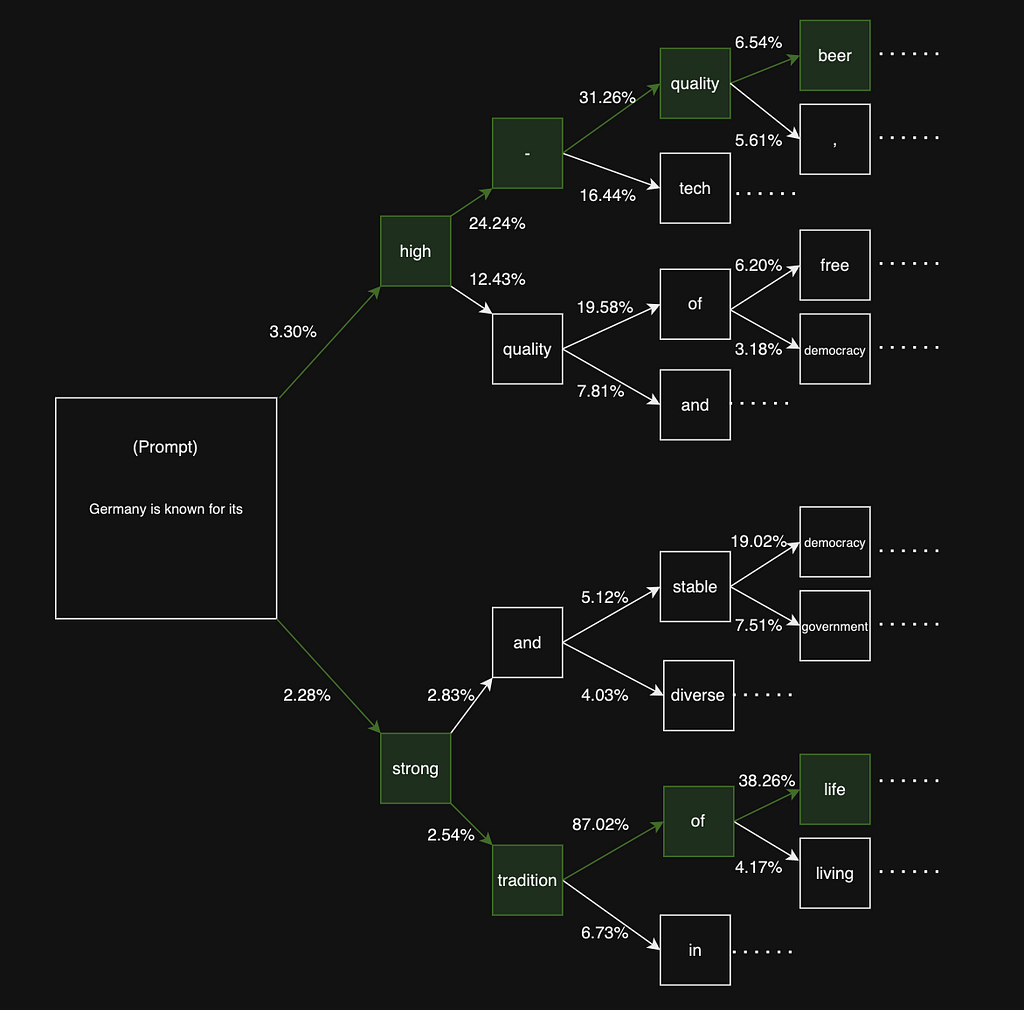 greedy search vs beam search(image by the author)
greedy search vs beam search(image by the author)Lets calculate the join probabilities of the green sequences above.
Germany is known for its -> high-quality beer…
with the joint probability 3.30%*24.24%*31.26%*6.54% = 0.0016353
whereas the lower path with the sequence;
Germany is known for its -> strong tradition of life…
2.28%*2.54%*87.02%*38.26% = 0.0019281.
The bottom sequence overall resulted with the higher joint probability, although the first next token prediction step in the top sequence has higher probability.
While greedy search priorities the absolute maximum probability at each prediction step, it neglects the token probabilities in sequences. Beam search decoding enables us to go in depth of sequences and help us decode text in more extensive fashion. So is beam-search the ultimate solution?
Lets explore further and decode the next 128 tokens with the depth of 5 beams.
"""Germany is known for its high-speed rail network, but the country is also home to some of the world's most beautiful natural landscapes.
Here are 10 of the most beautiful places in Germany.
1. Lake Constance
Lake Constance is one of the largest lakes in Germany.
It is located in the state of North Rhine-Westphalia and is the second largest lake in Germany after Lake Constance in Bavaria.
Lake Constance is located in the state of North Rhine-Westphalia and is the second largest lake in Germany after Lake Constance in Bavaria.
"""
Although comparatively lesser than the greedy-search, beam-search suffers from repetitive output too. However, with beam search decoding, we can solve this problem by penalising the repeated pairs of word sequences. In other words, the probability of token sequences is assigned zero, if the sequence has already been decoded before. This penalisation of a repeated tokens sequence is also know as n-gram penalty.
While “n” signifies the length of the sequence, “gram” is a term that refers to “unit” in computational linguistic often corresponds to the term token in our case.The reasoning behind is to discourage the generation of sequences that contain consecutive repeating n-grams. The decoding algorithm will penalise generated sequences that contain repeating pairs of words in the output.
Knowing this, let’s apply n-gram penalty of n = 2.
"""Germany is known for its high-speed rail network, but the country is also home to some of the world's most beautiful natural landscapes, including the Alps, the Baltic Sea, and Lake Constance.
The country's capital, Berlin, is the largest city in Europe, with a population of more than 8.5 million people.
The city is located in the former East Germany, which was divided into East and West Germany after World War II.
Today, Germany is a member of both the European Union and NATO, as well as the World Trade Organization and the Organization for Economic Cooperation and Development (OECD).<|endoftext|>
"""
This is the best completion of the input prompt we extracted from the model so far in terms of coherence and compactness. Through n-gram penalisation the output decoded with beam-search became more human-like.
When should we use beam-search and when greedy-search? Where the factualness is paramount, like solving a math problem, key information extraction, summarisation or translation, greedy-search should be preferred. However, when we want to achieve creative output and factuality is not our priority (like it can be in the case of story generation) beam-search is often the better suited approach.
Why exactly does your prompt matter? Because every word you choose to use, the sentence structure, the layout of your instructions will activate different series of parameters in the deep layers of large language model and the probabilities will be formed differently for each different prompt. In the essence of the matter, the text generation is a probability expression conditional on your prompt.
There are also alternative methods to prevent repetitions and influence the factuality/creativity of the generated text, such as truncating the distribution of vocabulary or sampling methods. If you are interested in a higher-level in-depth exploration of the subject, I’d highly recommend the article from Patrick von Platen in HuggingFace blog.
Next and the last article of this series will explore fine-tuning and reinforcement learning through human feedback which played an important role on why pre-trained models succeeded to surpass SOTA models in several benchmarks. I hope in this blog post, I was able help you understand the reasoning of prompt engineering better. Many thanks for the read. Until next time.
References:
*?—?Ilya Sutskever, at No Priors Ep. 39 | With OpenAI Co-Founder & Chief Scientist Ilya Sutskever link: https://www.youtube.com/watch?v=Ft0gTO2K85AL. Tunstall, L. von Werra, and T. Wolf, “Natural Language Processing with Transformers, Revised Edition,” O’Reilly Media, Inc., Released May 2022, ISBN: 9781098136796.Relevant links:Inside GPT?—?I : Understanding the text generation https://towardsdatascience.com/inside-gpt-i-1e8840ca8093How to generate text: using different decoding methods for language generation with Transformershttps://huggingface.co/blog/how-to-generate
Inside GPT?—?II : The Core Mechanics of Prompt Engineering was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.



