


Ask an LLM a question without leaking private informationImage generated by the author, with help from openart.aiI have to admit that I was initially skeptical about the ability of Large Language Models (LLM) to generate code snippets that actually...
Ask an LLM a question without leaking private information
 Image generated by the author, with help from openart.ai
Image generated by the author, with help from openart.aiI have to admit that I was initially skeptical about the ability of Large Language Models (LLM) to generate code snippets that actually worked. I tried it expecting the worst, and I was pleasantly surprised. Like any interaction with a chatbot, the way the question is formatted matters, but with time, you get to know how to specify the boundaries of the problem you need help�with.
I was getting used to having an online chatbot service always available while writing code when my employer issued a company-wide policy prohibiting employees from using it. I could go back to my old googling habits, but I decided to build a locally running LLM service that I could question without leaking information outside the company walls. Thanks to the open-source LLM offering on HuggingFace, and the chainlit project, I could put together a service that satisfies the need for coding assistance.
The next logical step was to add some voice interaction. Although voice is not well-suited for coding assistance (you want to see the generated code snippets, not hear them), there are situations where you need help with inspiration on a creative project. The feeling of being told a story adds value to the experience. On the other hand, you may be reluctant to use an online service because you want to keep your work�private.
In this project, I�ll take you through the steps to build an assistant that allows you to interact vocally with an open-source LLM. All the components are running locally on your computer.
Architecture
The architecture involves three separate components:
A wake-word detection serviceA voice assistant serviceA chat�service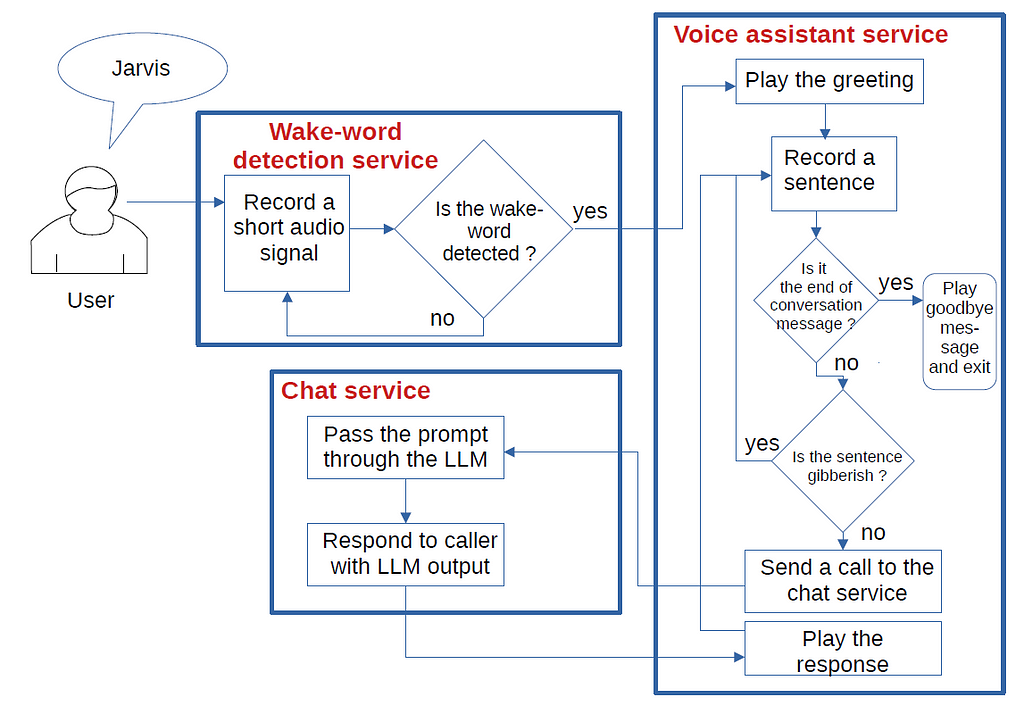 Flowchart of the three components. Image by the�author.
Flowchart of the three components. Image by the�author.The three components are standalone projects, each having its own github repository. Let�s walk through each component and see how they interact.
Chat service
The chat service runs the open-source LLM called HuggingFaceH4/zephyr-7b-alpha. The service receives a prompt through a POST call, passes the prompt through the LLM, and returns the output as the call response.
You can find the code�here.
In��/chat_service/server/, rename chat_server_config.xml.example to chat_server_config.xml.
You can then start the chat server with the following command:
python .\chat_server.pyWhen the service runs for the first time, it takes several minutes to start because large files get downloaded from the HuggingFace website and stored in a local cache directory.You get a confirmation from the terminal that the service is�running:
 Confirmation that the chat service is running. Image by the�author.
Confirmation that the chat service is running. Image by the�author.If you want to test the interaction with the LLM, go to��/chat_service/chainlit_interface/.
Rename app_config.xml.example to app_config.xml. Launch the web chat service�with
.\start_interface.shBrowse to the local address localhost:8000
You should be able to interact with your locally running LLM through a text interface:
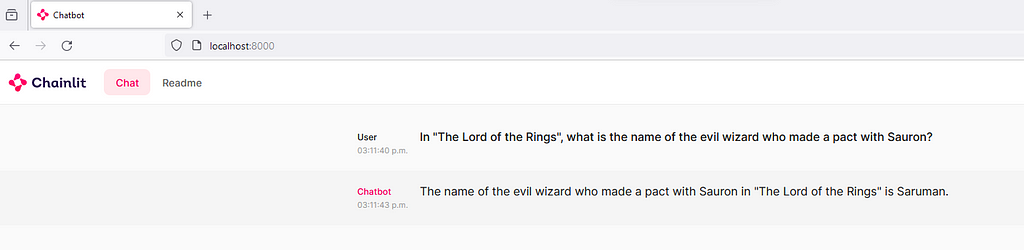 Text interaction with the locally running LLM. Image by the�author.
Text interaction with the locally running LLM. Image by the�author.Voice assistant service
The voice assistant service is where the speech-to-text and text-to-speech conversions happen. You can find the code�here.
Go to��/voice_assistant/server/.
Rename voice_assistant_service_config.xml.example to voice_assistant_service_config.xml.
The assistant starts by playing the greeting to indicate that it is listening to the user. The greeting text is configured in voice_assistant_config.xml, under the element <welcome_message>:
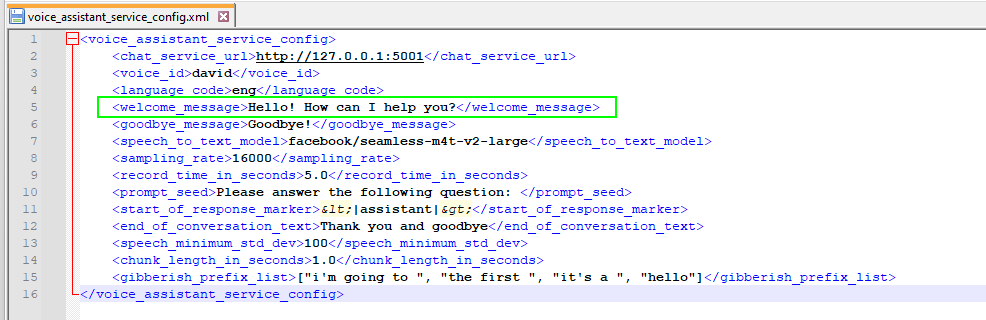 The voice_assistant_config.xml file. Image by the�author.
The voice_assistant_config.xml file. Image by the�author.The text-to-speech engine that allows the program to convert text into spoken audio that you can hear through your audio output device is pyttsx3. From my experience, this engine speaks with a reasonably natural tone, both in English and in French. Unlike other packages that rely on an API call, it runs�locally.
A model called facebook/seamless-m4t-v2-large performs the speech-to-text inference. Model weights get downloaded when voice_assistant_service.py is first�run.
The principal loop in voice_assistant_service.main() performs the following tasks:
Get a sentence from the microphone. Convert it to text using the speech-to-text model.Check if the user spoke the message defined in the <end_of_conversation_text> element from the configuration file. In this case, the conversation ends, and the program terminates after playing the goodbye�message.Check if the sentence is gibberish. The speech-to-text engine often outputs a valid English sentence, even if I didn�t say anything. By chance, these undesirable outputs tend to repeat themselves. For example, gibberish sentences will sometimes start with �[� or �i�m going to�. I collected a list of prefixes often associated with a gibberish sentence in the <gibberish_prefix_list> element of the configuration file (this list would likely change for another speech-to-text model). Whenever an audio input starts with one of the prefixes in the list, then the sentence is�ignored.If the sentence doesn�t appear to be gibberish, send a request to the chat service. Play the response.https://medium.com/media/d99d3beed448a6c31693e459384430cd/hrefWake-word service
The last component is a service that continually listens to the user�s microphone. When the user speaks the wake-word, a system call starts the voice assistant service. The wake-word service runs a smaller model than the voice assistant service models. For this reason, it makes sense to have the wake-word service running continuously while the voice assistant service only launches when we need�it.
You can find the wake-word service code�here.
After cloning the project, move to��/wakeword_service/server.
Rename wakeword_service_gui_config.xml.example to wakeword_service_gui_config.xml.
Rename command.bat.example to command.bat. You�ll need to edit command.bat so the virtual environment activation and the call to voice_assistant_service.py correspond to your directory structure.
You can start the service by the following call:
python gui.pyThe core of the wake-word detection service is the openwakeword project. Out of a few wake-word models, I picked the �hey jarvis� model. I found that simply saying �Jarvis?� will trigger the detection.
Whenever the wake-word is detected, a command file gets called, as specified in the <command_on_wakeword> element of the configuration file. In our case, the command.bat file activates the virtual environment and starts the voice assistant service.
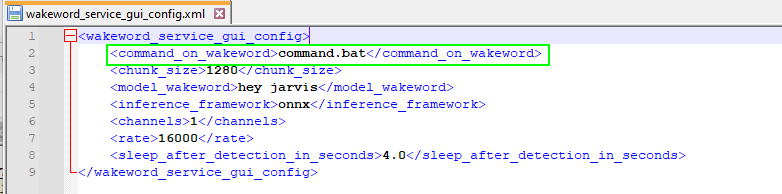 The configuration file of the wake-word detection service GUI. Image by the�author.
The configuration file of the wake-word detection service GUI. Image by the�author.If you want to use the wake-word detection service for something else, you can edit the command.bat file to make it start whatever program you�want.
When the wake-word is detected, the wake-word detection service emits a two-beep audio signal to indicate it was triggered. This quick feedback tells the user that they must wait as the text-to-speech and the speech-to-text models load in the computer�s GPU, which can take several seconds. When both models are loaded, the voice assistant service plays the greeting, and the conversation can begin. After the conversation ends, the voice assistant service terminates, and the wake-word detection service emits another two-beep�signal.
When the three components are installed and tested, we can start the chat and the wake-word detection services. The wake-word detection service will constantly listen to the microphone. When the wake-word gets detected (�Jarvis?�), it will start the voice assistant service. You can then ask questions out loud and receive a spoken answer. When the end-of-conversation phrase (�Thank you and goodbye�) is detected, the voice assistant service�ends.
Example of an interaction with the assistant
Here is an example of an interaction with the voice assistant:
�Jarvis?� [beep-beep][Several seconds of silence as the voice assistant models�load]�Hello! How can I help�you?��What are Saturn�s rings made�of?��Saturn�s rings are primarily composed of ice particles, with the majority being made up of water ice. However, there are also smaller amounts of other ices, such as ammonia ice and rocky debris, in the rings. The exact composition of the rings varies depending on the distance from Saturn, with the inner rings being denser and made up of smaller particles, while the outer rings are more spread out and contain larger ice particles.��Tell me the plot of the movie �Back to the Future�.��The movie �Back to the Future� follows the story of Marty McFly, a high school student who is accidentally transported back to 1955 in a time-traveling DeLorean car created by his eccentric scientist friend, Doc Brown. Marty must navigate the challenges of the past while trying to repair the damage to the present and prevent his teenage mother from falling in love with his teenage father. Along the way, Marty befriends a younger version of Doc Brown and helps him overcome a personal tragedy. The movie explores themes of fate, family, and the consequences of altering the�past.��Thank you and�goodbye��Goodbye� [beep-beep]Conclusion
In this project, we implemented a voice assistant system composed of a wake-word detection service, a voice assistant service, and a chat service. Each one of these components is a standalone building block reusable for other projects.
Among the many surprises I had while working on this voice assistant, what struck me the most was the quality of the speech-to-text conversion. If you�re like me, you have probably struggled with automated voice recognition systems that fail to transcribe simple commands such as �Turn down the volume�! I expected speech-to-text conversion to be the main stumbling block of the pipeline. After experimenting with a few unsatisfying models, I landed on facebook/seamless-m4t-v2-large and was impressed with the quality of the results. I can even speak a sentence in French, and the neural network will automatically translate it into English. Nothing less than�amazing!
I hope you�ll try this fun project, and let me know what you use it�for!
Build a Locally Running Voice Assistant was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.