


2024 could be the tipping point of Music�AIImage Generated with DALL-E�3.Recap: How 2023 Changed Music�AIFrom my perspective, 2023 was the most exciting year for Music AI in the history of the field. Here are only some of the breakthroughs...
2024 could be the tipping point of Music�AI
 Image Generated with DALL-E�3.
Image Generated with DALL-E�3.Recap: How 2023 Changed Music�AI
From my perspective, 2023 was the most exciting year for Music AI in the history of the field. Here are only some of the breakthroughs we got to experience in this amazing�year:
Text-to-Music generation has crossed Uncanny Valley (e.g.�MusicLM)Open-Source melody-conditioned music generation released (e.g. MusicGen)First prompt-based music search products launched (e.g.�Cyanite)Open-source chatbots with audio understanding/generation capabilities were made available (e.g. AudioGPT)Open-source music description AI was released (e.g. Doh et al.,�2023)Prompt-based source separation piloted (e.g. Liu et al.,�2023)�From text-to-music generation to full-text music search, 2023 was rich with breakthroughs. These advancements are just the tip of the iceberg, showcasing the potential that lies within Music AI. However, even with all these exciting developments, the field is still noticeably lagging behind its bigger brother Speech AI, or even its cousins NLP & Computer Vision. This gap is observable (or audible) in two key�ways:
1. The tech is not mature enough. Whether it is music generation, text-based search, or neural embeddings: Everything we have in music AI today has been available in the text & image domain for at least 1�3 years. The field needs more funding, time, and brain�power.
2. Lack of convincing and popular commercial products. After the potential of music AI became clear, a whole bunch of startups formed to start working on commercial products. However, as these products are being developed and tested, musicians and businesses eagerly await their chance to integrate AI tech into their workflows.
After the technological success of music AI in 2023, however, I am optimistic that researchers & companies will be working hard to make progress in both of these dimensions. In this post, I want to highlight three specific developments I hope to see in 2024 and explain why they would be important. With these expected advancements, 2024 stands on the brink of revolutionizing how we interact with music through�AI.
1. Flexible and Natural Source Separation
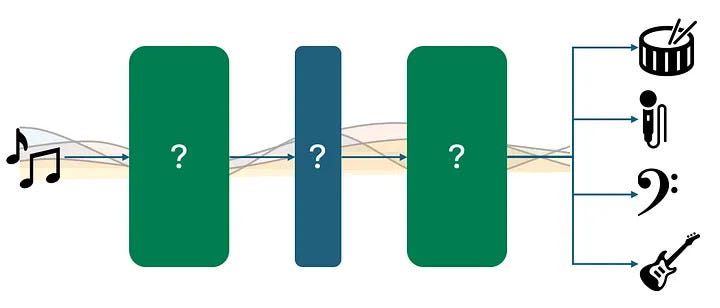 Source separation visualized. Image taken from this blog post by the�author.
Source separation visualized. Image taken from this blog post by the�author.What is Source Separation?
Music source separation is the task of splitting a fully produced piece of music into its original instrument sources (e.g. vocals, rhythm, keys). If you have never heard about source separation, I have written a full blog post about how it works and why it is such a challenging technological problem.
The first big breakthrough in source separation happened in 2019 when Deezer released Spleeter as an open-source tool. Since this technological leap, the field has experienced rather steady, small steps of improvement. Still, if you compare the original Spleeter to modern open-source tools like Meta�s DEMUCS or commercial solutions like LALAL.ai, it feels like a night and day difference. So, after years of slow, incremental progress, why would I expect source separation to blow up in�2024?
Why Should We Expect Breakthroughs in Source Separation?
Firstly, source separation is a keystone technology for other music AI problems. Having a fast, flexible, and natural-sounding source separation tool could bring music classification, tagging, or data augmentation to the next level. Many researchers & companies are carefully observing advancements in source separation, ready to act when the next breakthrough occurs.
Secondly, different kinds of breakthroughs would move the field forward. The most obvious one is an increase in separation quality. While we will surely see advancements in this regard, I do not expect a major leap here (happy to be proven wrong). Still, aside from output quality, source separation algorithms have two other problems:
1. Speed: Source separation often runs on large generative neural networks. For individual tracks, this might be fine. However, for larger workloads that you would encounter in commercial applications, the speed is usually still too slow?�?especially if source separation is performed during inference.
2. Flexibility: In general, source separation tools offer a fixed set of stems (e.g. �vocals�, �drums�, �bass�, �other�). Traditionally, there is no way to perform customized source separation tailored to the user's needs, as that would require training a whole new neural network on this�task.
Many interesting applications emerge once source separation is fast enough to perform during inference (i.e. before every single model prediction). For example, I have written about the potential of using source separation for making black-box music AI explainable. I would argue that there is significant commercial interest in speed optimization which might drive a breakthrough next�year.
Further, the limited flexibility of current-gen source separation AI makes it unusable for various use cases, even though the potential is there, in principle. In a paper called Separate Anything You Describe, researchers introduced a prompt-based source separation system, this year. Imagine typing �give me the main synth in the second verse, but without the delay effect� into a text box, and out comes your desired source audio. That�s the potential we are looking�at.
Summary: Source Separation
In summary, music source separation is likely to make big strides in 2024 due to its importance in music AI and ongoing improvements in speed and flexibility. New developments, like prompt-based systems, are making it more user-friendly and adaptable to different needs. All this promises a wider use in the industry, which could motivate research breakthroughs in the�field.
2. General-Purpose Music Embeddings
 Image generated with DALL-E�3.
Image generated with DALL-E�3.Embeddings in Natural Language Processing (NLP)
To understand what music embeddings are and why they matter, let us look at the field of Natural Language Processing (NLP), where this term originates from. Before the advent of embeddings in NLP, the field primarily relied on simpler, statistics-based methods for understanding text. For instance, in a simple bag-of-words (BoW) approach, you would simply count how often each word in a vocabulary occurs in a text. This makes BoW no more useful than a simple word�cloud.
 An example of a simple word cloud. Image by�Author.
An example of a simple word cloud. Image by�Author.The introduction of embeddings significantly changed the landscape of NLP. Embeddings are mathematical representations of words (or phrases) where the semantic similarity between words is reflected in the distance between vectors in this embedding space. Simply put, the meaning of words, sentences, or entire books can be crunched into a bunch of numbers. Oftentimes, 100 to 1000 numbers per word/text are already enough to capture its meaning, mathematically.
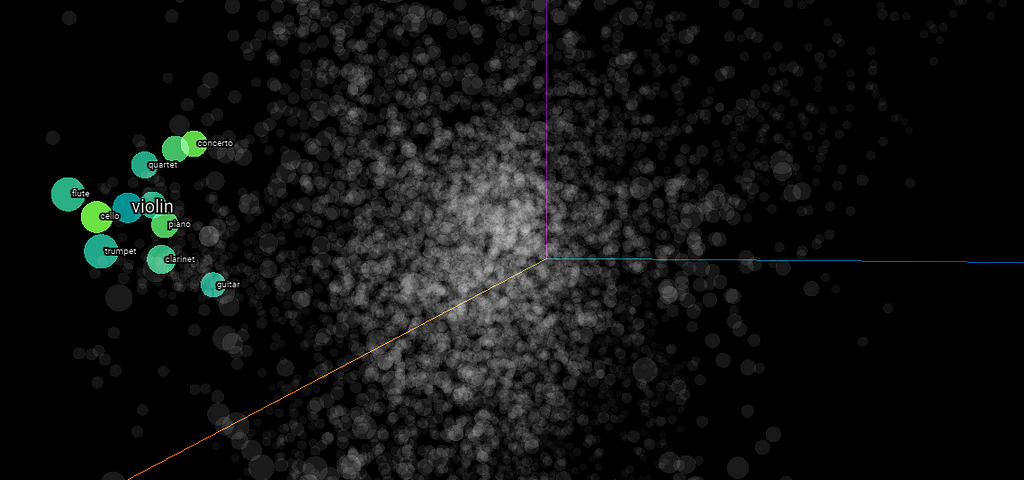 Word2Vec (10k) embeddings visualized with t-SNE on the Tensorflow Embedding Projector. The top 5 most similar words to �violin� are highlighted. Screenshot by�Author.
Word2Vec (10k) embeddings visualized with t-SNE on the Tensorflow Embedding Projector. The top 5 most similar words to �violin� are highlighted. Screenshot by�Author.In the figure above, you can see 10,000 words represented in a 3-dimensional chart, based on their numerical embeddings. Because these embeddings capture each word�s meaning, we can simply look for the closest embeddings in the chart to find similar terms. This way, we can easily identify the 5 most similar terms to �violin�: �cello�, �concerto�, �piano�, �sonata�, and �clarinet�.
Key advantages of embeddings:
Contextual Understanding: Unlike earlier methods, embeddings are context-sensitive. This means the same word can have different embeddings based on its usage in different sentences, granting a more nuanced understanding of language.Semantic Similarity: Words with similar meanings are often close together in the embedding space, which makes embeddings predestined for retrieval tasks found in music search engines or recommender systems.Pre-Trained Models: With models like BERT, embeddings are learned from large corpora of text and can be fine-tuned for specific tasks, significantly reducing the need for task-specific data.Embeddings for�Music
Because embeddings are nothing more than numbers, everything can be crunched into a meaningful embedding, in principle. An example is given in the following figure, where different music genres are visualized in a two-dimensional space, according to their similarity.
 Music genre embeddings visualized in a 2-dimensional space on Every Noise at Once. Screenshot by�Author.
Music genre embeddings visualized in a 2-dimensional space on Every Noise at Once. Screenshot by�Author.However, while embeddings have been successfully used in industry and academia for more than 5 years, we still have no widely adopted domain-specific embedding models for music. Clearly, there is a lot of economic potential in leveraging embeddings for music. Here are a few use cases for embeddings that could be instantly implemented at minimal development effort, given access to high-quality music embeddings:
Music Similarity Search: Search any music database for similar tracks to a given reference track.Text-to-Music Search: Search through a music database with natural language, instead of using pre-defined tags.Efficient Machine Learning: Embedding-based models often require 10�100 times less training data than traditional approaches based on spectrograms or similar audio representations.In 2023, we already made a lot of progress toward open-source high-quality music embedding models. For instance, Microsoft and LAION both released separately trained CLAP models (a specific type of embedding model) for the general audio domain. However, these models were mostly trained on speech and environmental sounds, making them less effective for music. Later, both Microsoft and LAION released music-specific versions of their CLAP models that were solely trained on music data. M-A-P has also released multiple impressive music-specific embedding models this�year.
My impression after testing all these models is that we are getting closer and closer, but have not even achieved what text-embeddings could do 3 years ago. In my estimation, the primary bottleneck remains data. We can assume that all major players like Google, Apple, Meta, Spotify, etc. are already using music embedding models effectively, as they have access to gigantic amounts of music data. However, the open-source community has not quite been able to catch up and provide a convincing model.
Summary: General-Purpose Music Embeddings
Embeddings are a promising technology, making retrieval tasks more accurate and enabling machine learning when data is scarce. Unfortunately, a breakthrough domain-specific embedding model for music is yet to be released. My hope and suspicion is that open-source initiatives or even big players committed to open-source releases (like Meta) will solve this problem in 2024. We are already close and once we reach a certain level of embedding quality, every company will be adopting embedding-based music tech to create much more value in a much shorter�time.
3. Bridging the Gap Between Technology and Practical Application
 Image generated with DALL-E�3.
Image generated with DALL-E�3.2023 was a weird year� On the one hand, AI has become the biggest buzzword in tech, and use cases for ChatGPT, Midjourney, etc. are easy to find for almost any end user and business. On the other hand, only a few actual finalized products have been launched and widely adopted. Of course, Drake can now sing �My Heart Will Go On�, but no business case has been constructed around this tech, so far. And yes, AI can now generate vocal samples for beat producers. However, in reality, some composers are making the effort to fine-tune their own AI models for the lack of attractive commercial solutions.
In that light, the biggest breakthrough for Music AI might not be a fancy research innovation. Instead, it might be a leap in the maturity of AI-based products and services that serve the needs of businesses or end-users. Along this path, there are still plenty of challenges to solve for anyone wanting to build Music AI products:
Understanding the Music Industry�s or End-User�s Needs: The tech itself is often quite use-case-agnostic. Finding out how the tech can serve real needs is a key challenge.Turning Fancy Demos into Robust Products: Today, a data scientist can build a chatbot prototype or even a music generation tool in a day. However, turning a fun demo into a useful, secure, and mature product is demanding and time-consuming.Navigating Intellectual Property & Licensing Concerns: Ethical and legal considerations are leaving companies and users hesitant to provide or adopt AI-based products.Securing Funding/Investment and First Income Streams: In 2023, countless Music AI startups have been founded. A strong vision and a clear business case will be mandatory to secure funding and enable product development.Marketing and User Adoption: Even the greatest innovative products can easily go unnoticed, these days. End-users and businesses are swarmed with reports and promises about the future of AI, making it challenging to reach your target audience.As an example, let us look a bit closer at how AI already impacts music production through new plugins for digital audio workstations (DAW). In a recent blog post, Native Instruments presents 10 new AI-power plugins. To showcase what is already possible, let us look at �Emergent Drums 2� by Audialab. Emergent Drums allows musicians to design their drum samples from scratch with generative AI. The plugin is nicely integrated into the DAW and functions as a fully-fledged drum machine plugin. Have a look at it yourselves:
https://medium.com/media/5f8b2a6bd041bf33ad97d9d08d4b5edc/hrefZooming out again, the potential applications for Music AI are vast, ranging from music production to education or marketing & distribution. Leveraging the immense technological potential of AI to provide real value in these domains will be a key challenge to solve in the upcoming�year.
Summary: From Research to�Products
2023 was a landmark year for Music AI, setting the stage for what�s next. The real game-changer for 2024? It is not just about the tech?�?it is about making it work for real people, in real scenarios. Expect to see Music AI stepping out of the lab and into our lives, influencing everything from how we create to how we consume�music.
Hello, 2024.
2023 has set the technological groundwork and created public awareness for AI and its possibilities. That is why, in my estimation, 2024 might be the best year to get started developing Music AI products. Of course, many of these products will fail and some of AI�s promises will fizzle out eventually. Looking at the well-known Garter Hype Cycle in the figure below, we should remind ourselves that this is normal and to be expected.
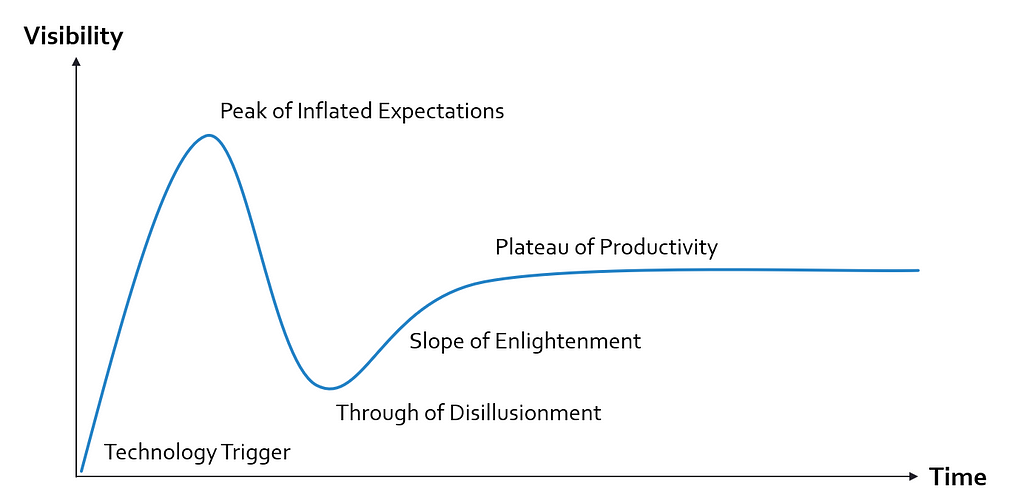 Gartner Hype Cycle. Image by�author.
Gartner Hype Cycle. Image by�author.Nobody can tell with certainty where we currently are on this hype cycle (if someone can, please let me know). Still, with all the groundwork and public awareness created this year, 2024 has the potential to become the historical landmark year for AI-based music technology. I am more than excited to see what the next year will�bring.
What a great time to be a musician!
About Me
I�m a musicologist and a data scientist, sharing my thoughts on current topics in AI & music. Here is some of my previous work related to this�article:
How Meta�s AI Generates Music Based on a Reference Melody: https://medium.com/towards-data-science/how-metas-ai-generates-music-based-on-a-reference-melody-de34acd783MusicLM: Has Google Solved AI Music Generation?: https://medium.com/towards-data-science/musiclm-has-google-solved-ai-music-generation-c6859e76bc3cAI Music Source Separation: How it Works and Why it is so Hard: https://medium.com/towards-data-science/ai-music-source-separation-how-it-works-and-why-it-is-so-hard-187852e54752Find me on Medium and Linkedin!
3 Music AI Breakthroughs to Expect in 2024 was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story.