


Daniel Wagner, Chief Scientist at�DAQRIUntil recently, the high-quality experiences that modern AR and VR systems enable at home were only possible with expensive, custom solutions in research labs or commercial setups. The new wave of AR and VR began...
Daniel Wagner, Chief Scientist at�DAQRI
Until recently, the high-quality experiences that modern AR and VR systems enable at home were only possible with expensive, custom solutions in research labs or commercial setups. The new wave of AR and VR began when Oculus and HTC released their Oculus Rift and HTC Vive products in 2016. Suddenly, technology that was once extremely expensive became more broadly accessible, with some users able to use these systems in their own homes. Still, these tethered systems rely on high-end computers and the use of �outside-in tracking,� meaning that stationary devices must be installed in the environment in order to build the tracking infrastructure for measuring user position and orientation.
Since then, newer systems such as Microsoft Mixed Reality, Oculus Go, and HTC Vive Focus have progressed to inside-out tracking. These newer systems do not rely on prepared environments, which significantly reduces the burden of setting the system up. Similarly, on the AR side, systems like DAQRI Smart Glasses� and Microsoft HoloLens leverage inside-out tracking to enable true mobility. All these systems use some form of visual-inertial fusion to achieve a level of latency that remains relatively unnoticeable to�humans.
In this article, we�ll take a deep dive into the technologies used by these AR and VR systems and see how the three key components (inertial measurement units (IMUs), prediction, and late correction) are combined into pipelines with end-to-end latencies of just a few milliseconds. Due to the significantly higher challenges mobile AR systems must overcome in comparison to stationary VR systems, we�ll focus exclusively on mobile AR�systems.
LATENCY
Latency, or �motion to photon latency,� is a critical property of all AR and VR systems. It describes the length of time between the user performing a motion (e.g., turning the head to the left) and the display showing the appropriate content for that particular motion (e.g., the content on the head mounted display (HMD) subsequently moving to the right). The term �photon� indicates that all parts of the display system are involved in this process, up until the point when photons are emitted from the�display.
Humans are highly perceptive to latency. In VR, perception of misalignment originates from both muscle motion and the vestibular system (within the ear), as the user only sees virtual content. In these systems, up to 20 milliseconds of lag can remain undetected by the user. In AR, optical see-through (OST) systems are commonly used to overlay virtual content onto the real-world. Since there is no lag in the real world, latency in such AR systems becomes visually apparent in the form of misregistration between virtual content and the real world. Since the human visual system is extremely sensitive to lag, 5 milliseconds of latency or less is required in OST systems in order to remain unnoticed by the�user.
Achieving such low latencies is more complicated than one might think, especially since each step taken by the system contributes to the overall latency. At a high level, the pipeline of measuring a motion to showing updated content on the display consists of the following main�blocks:
Sensors (camera and�IMU)Tracking (motion estimation)Rendering (image generation)Display (image presentation)Let�s assume these four main blocks apply to a well-designed and implemented AR/VR system, where external factors such as copying or locking buffers and queueing at the operating system level do not add unnecessary latency.
After investigating each block, we will see that a na�ve implementation of this pipeline can easily result in over 100ms of latency. After separately evaluating the latency of each block, we�ll discuss how the end-to-end latency can be decreased to meet the 5ms requirement of AR�systems.
 End-to-end pipeline of an AR/VR�system
End-to-end pipeline of an AR/VR�systemSENSORS
Most mobile AR and VR devices today use a combination of cameras and inertial measurement units (IMUs) for motion estimation (inside-out pose tracking). We will see that the IMU is important for both robust pose (position and orientation of the device) estimation and low end-to-end latency.
AR and VR systems typically run tracking cameras at 30Hz, which means that an image can be read out and passed on for processing every 33ms. Further, a frame rate of 30Hz puts an upper limit of 33ms exposure time per�frame.
Let�s assume the exposure is fixed at 20ms. For later processing, we must first assign a timestamp to each sensor measurement. For the actual exposure, the start and end times are defining factors. From a processing point of view, however, it is more convenient to use the point in time right in the middle of exposure. Therefore, when exposure ends, the age of the image is equal to half the exposure time. Thus, in our example, the image is already 10ms old. Once exposure completes, the image must be read out and forwarded to the image processing system. For our system, this takes another 5ms, making our image 15ms old at that time, even if the tracker starts processing the image immediately.
While cameras typically run at 30�60Hz, IMUs operate at a much higher rate of hundreds or even thousands of Hz. For our system, let�s assume the IMU runs at 1000 Hz and consequently generates a new sample every millisecond. IMU data is very compact (typically a few dozen bytes) and has very low latency, so it�s reasonable to assume that the latest IMU samples are approximately 1ms old at any given�time.
 Comparing sampling rates of IMU at 1000 Hz and camera at�30Hz
Comparing sampling rates of IMU at 1000 Hz and camera at�30HzTRACKING
Tracking consumes the sensor data to calculate a 6DOF motion estimation (pose), which describes how the device has moved and rotated. As mentioned above, the camera image that arrives at the tracking system is at least 15ms old. Alternatively, the IMU has much lower latency, with 1ms old IMU data readily available. However, IMU data that is newer than the camera frame is usually not processed at this�stage.
Since our example assumes the camera runs at 30Hz, the tracking system should operate at the same rate, providing a processing budget of up to 33ms. While it is possible to execute the processing of sequential camera frames in parallel to lend more processing time to each frame, this approach results in additional latency and therefore will not be used here. Instead, we�ll assume that the tracking system takes 25ms to finish processing the camera image plus IMU�data.
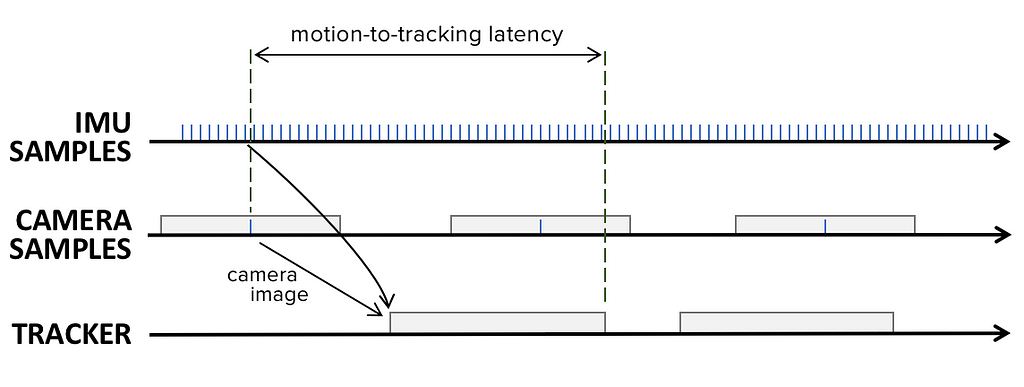 Latency from motion to pose estimation
Latency from motion to pose estimationSince camera frame processing can only begin once the frame becomes available to the tracker, the duration of sensor data acquisition and tracking are added together, resulting in 15ms + 25ms = 40ms of latency at the time we have a pose estimate. This pose is then passed on to the application for rendering.
RENDERING
Rendering is the step that generates a 2D image that is then sent to the display in the form of a frame buffer. To generate this image, the renderer requires several inputs, such as the 3D content that shall be displayed and the pose (view port) it is rendered from. Rendering operates at a different rate from pose estimation (typically at 60, 75 or 90Hz). As a result, it is fairly common to perform rendering asynchronously from tracking. With this in mind, let�s assume rendering operates at�60Hz.
When a new frame is generated, we can assume the renderer uses the latest camera pose estimated by the tracker. Since the tracker runs at 30Hz, this pose can be up to 33ms old. At 60Hz, the renderer produces a new frame approximately every 16.7ms. Only at the end of that 16.7ms period does the process of transmitting the frame to the display begin. This means it takes 16.7ms from the start of rendering until the frame buffer read-out�starts.
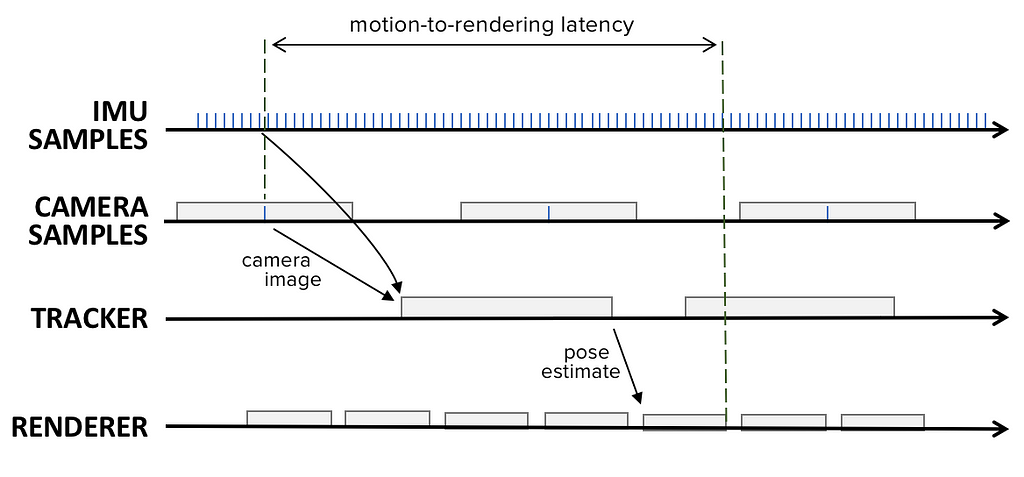 Latency from motion to rendered�image
Latency from motion to rendered�imageIn summation, the rendering block adds another 17�50ms in addition to the 40ms from previous blocks, putting us at 57�90ms of latency, far greater than the 5ms requirement.
DISPLAY
Most computer scientists don�t spend much time thinking about what happens to the frame buffer generated by the GPU once rendering has finished. For AR and VR, however, the way the display works is critical, as it adds a significant amount of additional highly-visible latency that must be addressed. As a result, understanding how displays work is fundamental to achieving low�latency.
When frame buffer read-out (also known as �scanout�) begins, data is sent pixel-by-pixel and line-by-line to the display. The specific display protocol (HDMI, DisplayPort, MIPI-DSI) is not important for our discussion, since all of these protocols behave similarly by sending the frame buffer only as quickly as needed for the given frame rate. As a result of running the display at 60Hz, it takes 1/60 of a second to transmit the frame to the display, adding another 17ms of�latency.
The AR and VR pipeline we have discussed so far has been fairly generic, but leads us to distinguish between different display types. Let�s discuss line-sequential displays, (e.g., LCD or OLED) and color-sequential displays (e.g.,LCOS).
LINE SEQUENTIAL DISPLAYS
Line-sequential displays are integrated into PC monitors, TVs, and VR headsets, and are the most common display type today. Each pixel in these systems stores the three primary colors (red, green and blue), so a frame�s data looks as follows: RGBRGBRGB�
This pattern indicates that the frames are organized as scanlines, where each scanline contains pixels and each pixel contains red, green and blue components. OLED and LCD displays do not typically store the received pixel data in a temporary buffer, unless they have to perform extra processing, such as rescaling. Instead, as data arrives, the display directly updates the corresponding pixel cells. Therefore, the top-most scanlines of the display (whose data arrives first) are updated around 16ms earlier than the bottom-most scanlines (whose data arrives last) of the same�frame.
Similarly, the bottom-most scanline of one frame is updated just before the top-most scanlines of the next frame are updated. Hence, latency of the top-most scanlines is very small (let�s assume 1ms), whereas the latency of the bottom-most scanlines is almost the length of a full frame time (16.7ms). The following figure illustrates the timings of this �rolling� update mechanism of a line sequential display.
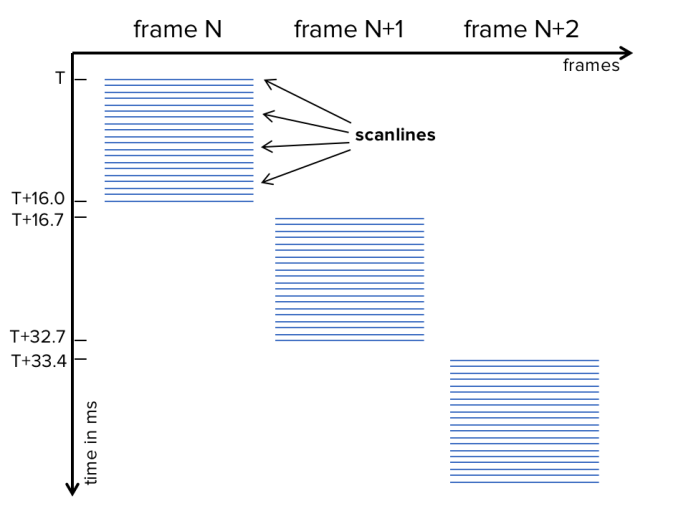 Hypothetical timings of a line sequential display. The first scanline of the frame N is shown at time T. The last scanline of the same frame is shown at T+16. Right after the v-blank, at T+16.7 the first scanline of frame N+1 is already displayed.
Hypothetical timings of a line sequential display. The first scanline of the frame N is shown at time T. The last scanline of the same frame is shown at T+16. Right after the v-blank, at T+16.7 the first scanline of frame N+1 is already displayed.COLOR SEQUENTIAL DISPLAYS
Today, LCOS are less common in consumer devices, but they are very common in mobile AR devices, such as DAQRI Smart Glasses and Microsoft HoloLens. LCOS can only show one color at a time. In order to display a full RGB frame, the LCOS display matrix is first updated for the red components of all pixels before the red LED is turned on to actually show the red image. Then, the red LED is turned off and the display matrix is reconfigured for the green components, activating the green LED and displaying the green image. This process is repeated for blue and (optionally) green�again.
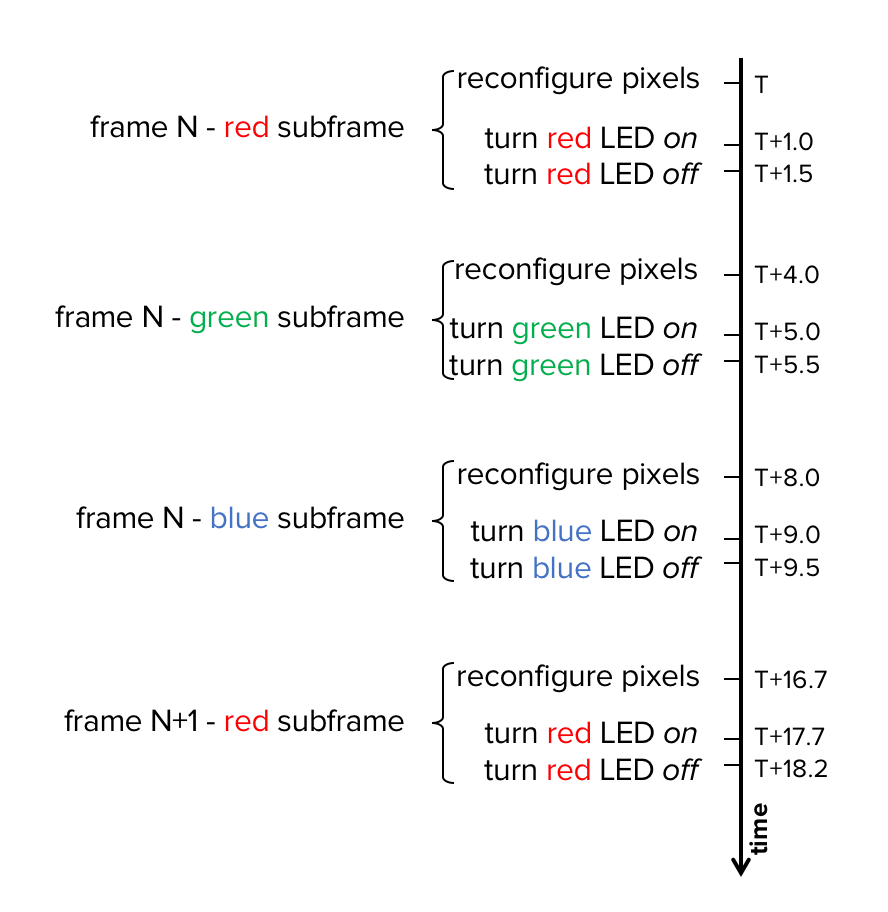 Hypothetical timings in milliseconds of a color sequential display running at 60Hz showing a frame (starting a time T) with three sub frames (red, green and�blue).
Hypothetical timings in milliseconds of a color sequential display running at 60Hz showing a frame (starting a time T) with three sub frames (red, green and�blue).This behavior has two important consequences. First, data sent to the LCOS needs to be organized in subframes of different colors rather than interleaved RGB frames. GPUs produce interleaved RGB frames by default, and display standards (such as HDMI and DisplayPort) work with interleaved RGB frames as well, so an additional color separation step (usually in the form of a hardware block) is needed before subframes can be passed on to the LCOS. However, since a color separated subframe isn�t available until the complete RGB frame has been received, one frame of latency is added as a consequence of this separation step?�?before even a single subframe has been displayed.
While HDMI and DisplayPort are slow by standard protocols, LCOS typically utilize fast, proprietary protocols. For example, it is common to take only ~1ms to send a separated subframe to an LCOS. As a result of using subframes, each color is displayed separately, meaning latency varies by color. Typical subframe sequences are red, green, blue, green, with an offset of 4ms each. Overall, at 60Hz it takes ~17ms to send the RGB frame from the GPU to the color separator and around 1ms to send the first subframe from the color separator to the LCOS. Each successive subframe is delayed by an additional offset, which we assume to be 4ms here. So, we get display latencies of 18ms for red, 22ms for green, 26ms for blue and 30ms for an optional second green subframe.
OVERALL LATENCY OF A NA�VE AR/VR�PIPELINE
Now that we�ve covered all four blocks, let�s see how their latencies sum�up:

It is clear that neither the overall latency in the OLED case nor the overall latency in LCOS case is sufficient for an AR or VR system. In fact, each block alone takes longer than the required 5ms for AR systems. Furthermore, the latency of the LCOS system is a factor of 15�24x away from those 5ms. How can we fix�this?
As evident in the table above, both rendering and display contribute to more than 50% of overall latency. Even more challenging, these variable latencies would create very unpleasant effects, such as jerky tracking and animations.
The three key technologies to reduce latency include IMU, prediction, and late correction. All three come into play in the rendering and display stage. This seems odd, as we have already accumulated 40ms of latency at that point in the process, but we�ll see how this latency can be �undone� several times allowing us to reach our 5ms�goal.
OVERCOMING SENSORS AND TRACKING�LATENCY
As mentioned above, when the renderer picks up the latest pose from the tracker, that pose can be anywhere between 40ms and 73ms old. Fortunately, a number of different methods can be used to reduce this latency. As we�ll see below, however, some of these solutions are accompanied by unfavorable consequences.
First, we could reduce camera exposure time, which would also have a positive effect on motion blur. However, small, low-cost cameras are typically unable to operate with lower exposure times without introducing severe noise artefacts. As a result, attaining less than 20ms of exposure is typically only possible in very well-lit environments, such as outdoors, disqualifying this as a viable solution.
Second, we could reduce the time it takes to process an image in the tracker by using faster tracking methods or processing units. However, faster methods generally equal less accuracy and/or robustness?�?two factors we don�t want to compromise. Additionally, faster processing units often require more power, which may or may not be deemed acceptable either. In this case, we can assume that a low-power CPU (e.g., a DSP or an ARM CPU) is used for tracking that does not have the power to run the tracker�faster.
Fortunately, the IMU comes to the rescue. In contrast to the camera, the IMU can run at nearly arbitrary sampling rates (compared to camera rates). Here we assume 1000Hz, which results in every sample being 1ms old at maximum. With proper visual inertial fusion, one can use the IMU data to calculate a relative motion path from one time stamp to another by integrating all IMU samples within that time span. Such a relative motion can be applied on top of an absolute pose to calculate a new absolute pose. Therefore, by taking the last pose from the tracker and all IMU samples since that point in time, we can calculate a new pose that is only around 1ms old. Integrating IMU data does have its limits, though, due to noise and accumulated drift. Nonetheless, for our purposes, it is a great solution that results in a roughly 1ms old pose (rather than 40�73ms) for the renderer.
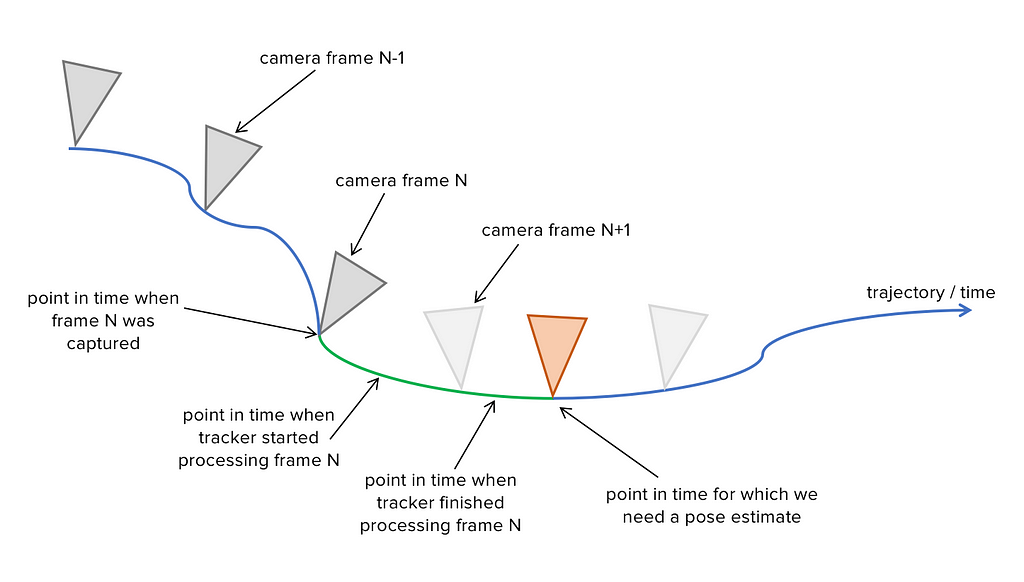 How captured frames, processed frames and start of render time are related. At the point in time we need a pose (orange triangle) the last processed frame (frame N) is already 40�73ms old (due to timings mentioned above). By using IMU data from frame N to �now� (green part of the trajectory), we can calculate a pose that is only ~1ms old. Another camera frame N+1 has already been captured, but since it hasn�t been processed yet, frame N is the last point in time for which there is a pose available from the�tracker.
How captured frames, processed frames and start of render time are related. At the point in time we need a pose (orange triangle) the last processed frame (frame N) is already 40�73ms old (due to timings mentioned above). By using IMU data from frame N to �now� (green part of the trajectory), we can calculate a pose that is only ~1ms old. Another camera frame N+1 has already been captured, but since it hasn�t been processed yet, frame N is the last point in time for which there is a pose available from the�tracker.OVERCOMING RENDERING AND DISPLAY�LATENCY
Using an up-to-date pose is undoubtedly preferred over an old pose, but it is not sufficient, as the pose will again be outdated by the time the rendered frame appears on the display. Fortunately, at the point in time when rendering begins, we do have a good estimate of how long it will take until the rendered frame appears on the display (when photons are emitted), since the display runs in sync with the GPU. So, rather than using the current pose, we should instead use the pose at that point of time in the future. Though we are unable to foresee the future, we can use models such as constant velocity, constant acceleration, and higher order motion curve fitting to make predictions based upon recent�motion.
Motion prediction works well when the time to predict forward is short?�?such as 20ms?�?but quickly degrades for longer periods. It is therefore common to post-correct the render output by warping the frame buffer after the render step with an even newer pose prediction. Since this warping is a pure 2D operation, it is much faster than the 3D scene rendering and its speed is independent of scene complexity. As a result, this can be executed in just a few milliseconds on a modern GPU, right before the frame buffer is sent to the display. This late correction (also called �late warping�) has been known in VR research since the 90s, but it was recently re-invented under the name �time warping�. While conceptually simple, late warping requires highly accurate timing and ideally the ability to interrupt the GPU during its current operation (also called preemption). Companies such as Oculus and Valve have been working with GPU manufacturers for years so that all modern GPUs support this feature very well today. The following figure shows how rendering and warping use different forward prediction times.
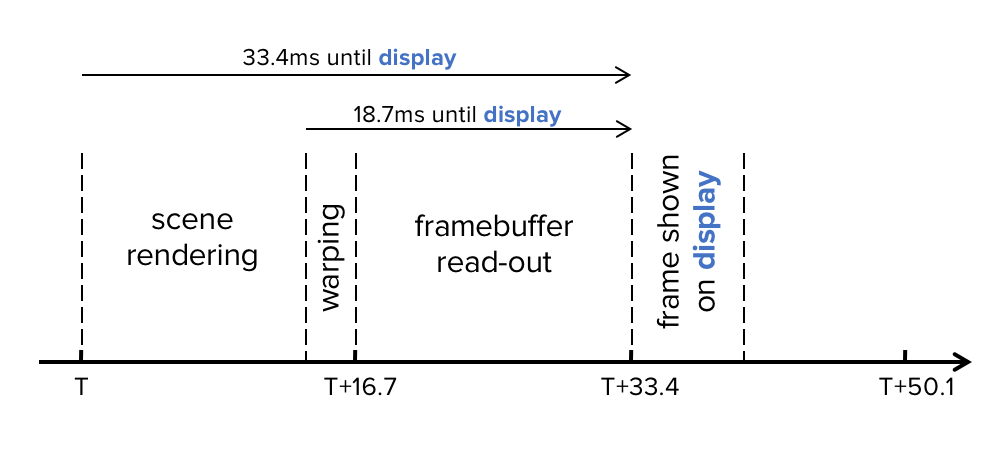 Scene rendering uses a pose predicted two full frames (33.4ms) into the future. Warping happens 2ms before frame end here, so it uses a pose 18.7ms into the�future.
Scene rendering uses a pose predicted two full frames (33.4ms) into the future. Warping happens 2ms before frame end here, so it uses a pose 18.7ms into the�future.At this point, we have reached the last step of our pipeline?�?optimizing the transfer of pixel data from GPU memory to the display. This step is highly dependent on the actual display technology. Let�s discuss the common solutions for OLED and LCOS, the two dominant mobile AR and VR display�types.
OLED DISPLAYS
OLEDs are commonly used in consumer VR displays. Compared to LCDs, OLEDs have lower pixel persistence. This leads to reduced latency and motion blur, which is essential for high quality AR and VR experiences. Today, most consumer VR devices, such as from Oculus, HTC, and Sony, use OLED displays as a result. On the AR side, the ODG R9 is a well-known device that uses an OLED display. At a high level, these displays function similarly to normal desktop monitors: pixel data is sent row-by-row from GPU memory to the display, and per default, the display updates the respective pixel cells directly without any further buffering. Transferring the framebuffer is done in �real-time,� meaning it takes the duration of one frame to transmit one framebuffer. Assuming the framebuffer is sent top to bottom, the top rows of the display will therefore be visible on the display almost immediately after the read-out started, whereas the bottom rows will not become visible until almost a full frame�later.
This behavior is the same for all the standard protocols, such as DisplayPort and HDMI in the PC domain and MIPI-DSI in the embedded space. On a desktop computer, this isn�t a problem, but in an AR or VR scenario, this behavior has noticeable consequences. Due to the time offset between top and bottom pixel rows, the rendered scene can suffer from shearing or other effects during motion, similar to a rolling shutter�camera.
The solution to this problem is to perform the late warping operation more than just once for the whole image. The image is instead segmented vertically into multiple tiles, where each tile is warped separately with a different pose. This staggered warping needs to be synchronized accurately with the framebuffer read-out. Right before the next tile is read-out, that same tile is generated by warping with the latest available pose. Conceptually, this is very similar to raster interrupt programming, which was popular in the 80s on home computers and game consoles.
For example, let�s say the display runs at 60Hz, meaning it takes about 16ms for a full frame to read out. If the framebuffer is split into 16 tiles, then each tile will be read-out and displayed around 1ms after the previous tile. Using this technique, we can reduce latency from GPU memory to photons to just a few milliseconds.
LCOS DISPLAYS
In contrast to OLEDs, there is no standard protocol for LCOS, and there are multiple LCOS manufacturers who provide quite different proprietary protocols. Let�s consider the HIMAX LCOS that is used in DAQRI Smart Glasses and apparently in Microsoft HoloLens as�well.
LCOS displays work very differently than OLED displays for multiple reasons. First, their mechanism for updating pixels operates much closer to that of DLP projectors than regular LCD or OLED displays. Further, the LCOS pixel matrix is updated while the LED is off so that the actual updating step isn�t visible. Once the pixel matrix has been fully updated, the LED is turned on, showing the entire new image at�once.
Second, while traditional displays show full RGB images, LCOS-based displays usually work color sequential: Only a single-color is shown at a time, typically in the order of red, green, blue, and green again. Between each shown color, the pixel matrix is updated to present the respective components of the pixels. This alternative mode is advantageous in that it prevents rolling updates as OLEDs do. However, it also has its disadvantages, such as color breakup (rainbow effect). Under motion, the time-separated colors lead to spatially separated colors, which is highly noticeable. This effect can be reduced by conducting pose prediction per color, but this subsequently creates some overhead and cannot perfectly reduce the breakup. Fortunately, the color sequential nature means the display operates at a much higher rate. Further, with the aforementioned RGBG sequence, the actual update rate of the display is not 60 full frames per second, but 240 sub frames per second. Since each subframe has only a single-color component, it is much more compact and can be transmitted to the display in less time than a full RGB frame. Let�s discuss how this technique can be used to reach extremely low latencies.
LCOS, such as the one from HIMAX, do not use standard protocols such as HDMI or DisplayPort. One reason behind this is that GPUs produce color sequential frame buffers per default, so some extra processing needs to occur to provide the framebuffer in the color sequential format the LCOS requires. LCOS manufacturers typically offer companion chips that receive framebuffers via common display standards, perform the required color separation step, and then pass the data on using a proprietary protocol. However, before an RGB frame can be color separated, it must be fully received by the companion chip, which takes a full frame time and adds significant delay.
Instead, it is more effective to execute the color separation on the host side (CPU and/or GPU), where it is done as part of the late warping step, and then transmit the single-color component frame buffers directly to the LCOS. The host would then warp the red components from the RGB frame buffer and transmit it to the LCOS for direct display. With the right time offset, the same operation is then repeated for green, blue and potentially green again for the same RGB frame. This approach is challenging to implement, as it requires both custom silicon for connecting the GPU to the LCOS directly, as well as the ability to warp the current frame while the next one is being rendered. Nonetheless, optimal implementations of this technique can achieve latencies of 1�2ms per color component from GPU to�photons.
LATENCY OF AN OPTIMIZED AR/VR�PIPELINE
So, how low can we get the motion-to-photon latency when considering all of the above techniques? To answer this question, we must first distinguish between display technologies (OLED vs LCOS), since they each require different methods and create different effects. Secondly, we must refine our definition of�latency.
Motion-to-photon latency is about two points in time: the point in time when a motion occurs, and the point in time when the resulting image becomes visible to the user. On the motion side, we must consider how we can use the measured motion. We initially wanted to use it as pose input to render the 3D scene, but once we realized this results in excessively high latencies, we extended our system with late warping. While this late warping does use pose input, it can only perform a very limited set of corrections, since it is applied on an already created 2D framebuffer. Fortunately, this limited set of corrections are sufficient in practice, so we will consider the time stamp of the warping pose for the motion�side.
On the display side, we saw that both OLED and LCOS produce artefacts due to the sequential nature of updating the display. We introduced warping per vertical tile to reduce latency of the scanline sequential displays, such as OLED, and we introduced warping per color component to reduce latency of color sequential displays, such as LCOS. Interestingly, the achievable latencies are similar in both cases, but one is in the spatial domain and the other is in the color�domain.
Taking this all into account, let�s look at an optimized AR pipeline with an LCOS-based display. We�ll use the numbers from the examples above, with just a few changes. We will assume that renderer and display run at 90Hz, as DAQRI Smart glasses do. We�ll also assume RGB subframes rather than RGBG subframes for the sake of simplicity. Finally, we�ll assume the LCOS is being connected to the GPU in such a manner that it receives subframes directly (we will not go into detail how such a connection could be implemented).
The figure below shows how all components work together in this system. As declared earlier, at the time the tracker picks up the camera image (see marker [1] in the figure below), it is already ~15ms old. The tracker adds another 25ms of latency, so by the time the pose becomes available [2], we already have a latency of ~40ms. When the renderer picks up the latest pose from the tracker, it uses all available IMU samples to calculate a pose plus camera motion that has only ~1ms of latency [3]. The renderer further estimates a pose that is forward predicted ~17 milliseconds into the future: 11ms for render time plus ~6ms for the display to show the middle (green) subframe.
In order to further improve our forward prediction, the system repeats this process in the late-warping step [4]. This warping is performed a total of three times?�?once for each subframe. Assuming 2ms for warping plus 2ms for readout and transfer into the LCOS, we must therefore forward predict only 4ms for each subframe. This reduces latency, leads to more accurate predictions, and introduces corrections per color channel to ultimately reduce color-breakup.
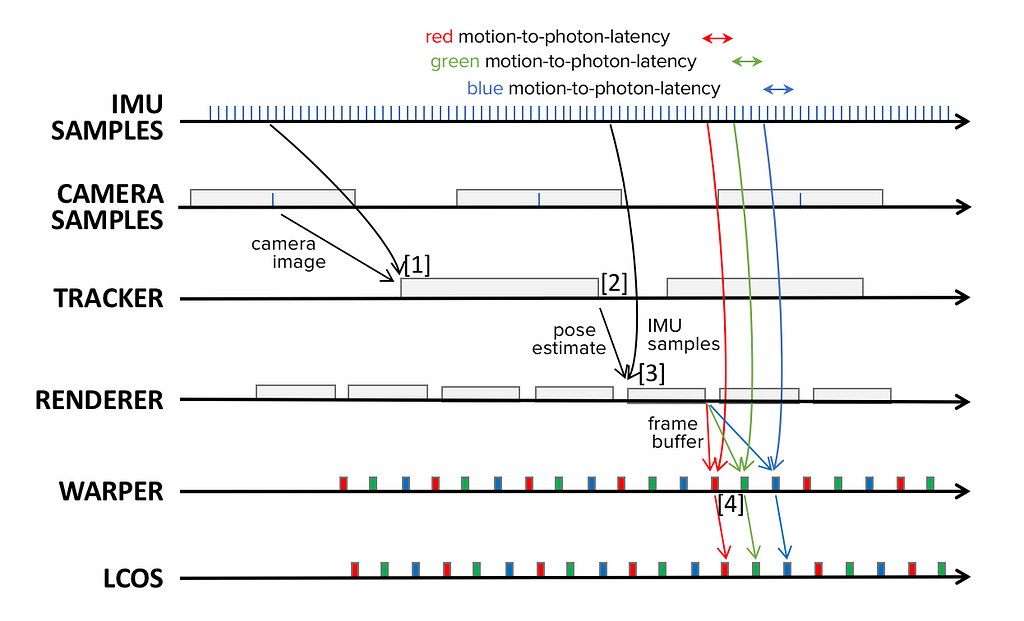 Timings and data flow of an optimized AR system with LCOS display: blue ticks represent time stamps of IMU and cameras samples. Black arrows represent data�flow.
Timings and data flow of an optimized AR system with LCOS display: blue ticks represent time stamps of IMU and cameras samples. Black arrows represent data�flow.Overall, what is the final latency we can achieve with such a system? The answer is: It depends. If we consider rendering using the latest 6DOF pose estimates as the last step in our pipeline that produces fully correct augmentations then achieving a latency of ~17ms is our best-case scenario.
However, late warping can correct most noticeable artefacts, so it makes sense to treat it as valid part of the pipeline. Without using forward prediction for late warping, we can achieve a physical latency of 4 milliseconds per color channel in our example system. However, 4 milliseconds is such a short length of time, making forward prediction almost perfect and pushing perceived latency towards zero. Further, we could actually predict beyond 4ms into the future to achieve a negative perceived latency. However, negative latency is just as unpleasant as positive latency, so this would not make sense for our scenario.
CONCLUSIONS
In this article, we described the challenges and approaches in dealing with latency in mobile AR and VR systems today. We saw that the required hardware and software solutions for these systems are dissimilar to gaming systems for monitors, where latency is of less concern. Additionally, mobile solutions have significantly less processing power than stationary systems?�?a problem that is usually addressed with more specialized hardware blocks in the form of DSPs, FPGAs or ASICs in order to successfully resolve the conflicting requirements for low power, low latency, and high throughput.
The overview presented here is largely conceptual, while real commercial systems must deal with numerous low-level details, from connecting a standard GPU to an LCOS to achieving highly accurate timings required for warping with tiling on a general-purpose architecture. Similarly, there are a number details on the software side that we did not discuss, such as enabling generic applications to take advantage of the low latency pipeline.
Lacking the required standards, these details are usually implemented in proprietary forms today. Display and display protocol standardization groups are already discussing extensions for improved AR and VR support, but it will take years for these extensions to mature and become available in products. Similarly, software like OpenVR and UnityXR continue to aim for standardization, but they have not reached product level yet. Until then, AR and VR device manufacturers will continue developing and promoting their proprietary solutions.






