


Better understand the basics of depth-sensing cameras, and learn how and where each class is utilized in the field of augmented realityThough this article primarily focuses on depth cameras for mobile AR, expect to learn about a variety of...
Better understand the basics of depth-sensing cameras, and learn how and where each class is utilized in the field of augmented reality
Though this article primarily focuses on depth cameras for mobile AR, expect to learn about a variety of depth cameras, if only for the benefit of better understanding the restrictions imposed by mobile AR use cases. Additionally, we�ll cover the whole range of depth cameras?�?those based on structured light (SL), passive stereo (PS), active stereo (AS) and time of flight (ToF). We will only consider solutions at a commercial level, thereby excluding research topics such as depth from a single image that may deliver impressive results, but are not up to the requirements of mobile�AR.
This article is written by Daniel Wagner, Chief Scientist at DAQRI. Before coming to DAQRI to lead the DAQRI Austria Research Center, Daniel was Senior Director of Technology at the Qualcomm Austria Research Center. He received his MSc from Vienna University of Technology and his Ph.D. from Graz University of Technology, and is well-known for pioneering the research area of AR on mobile�phones.
DEPTH CAMERAS FOR MOBILE�AR
Though depth cameras?�?cameras with the ability to capture 3D images?�?have been around for several decades, the general public was first exposed to this technology in 2010 with the introduction of the Microsoft Kinect as an accessory for the XBOX 360. Unfortunately, as with many cutting-edge products, and despite its impressive features, extensive press coverage, and significant financial backing, adoption of the Kinect was limited, leading to its recent discontinuation. More recently, we�ve seen similar technology integrated into Apple�s iPhone X as a front sensor bar that enables robust facial tracking and device unlocking.
While the above examples are clearly novel and entertaining, they are often considered to be somewhat gimmicky by those more familiar with the vast capabilities of depth cameras for mobile augmented reality (AR). More appropriately, high-end wearables such as Microsoft Hololens, Meta 2 and DAQRI Smart Glasses� include depth sensors for reasons outside of mere entertainment: the environmental understanding required by AR wearables is difficult to achieve with other types of sensors, and they are essential for natural, hands-free user input (such as gestures). I must admit, though, I haven�t seen a really convincing usage of gestures as an input mechanism.
With that being said, it�s important to appreciate and understand the surprisingly large variety of depth cameras, ranging from consumer solutions, as in the aforementioned iPhone X, to large, highly precise and expensive industrial solutions, as with the Mantis Vision F6 or the Ensenso cameras from IDS Imaging. While this white paper primarily focuses on depth cameras for mobile AR, expect to learn about a variety of depth cameras, if only for the benefit of better understanding the restrictions imposed by mobile AR use cases. What�s more, we�ll cover the whole range of depth cameras- those based on structured light (SL), passive stereo (PS), active stereo (AS) and time of flight (ToF). We will only consider solutions at a commercial level, thereby excluding research topics such as depth from a single image that may deliver impressive results, but are not up to the requirements of mobile�AR.
DEPTH CAMERA�BASICS
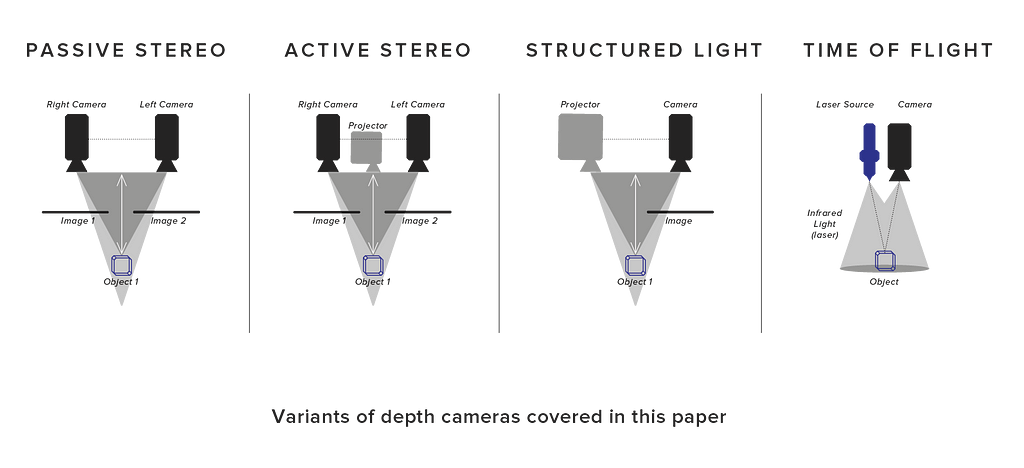
At present, the terms structured light and active stereo aren�t 100% clearly defined. However, for the purpose of this paper, let�s refer to structured light as a combination of a single-camera and a single-projector, where the projector projects a known pattern; as opposed to active stereo, which uses two cameras and a projector projecting an unknown (random)�pattern.
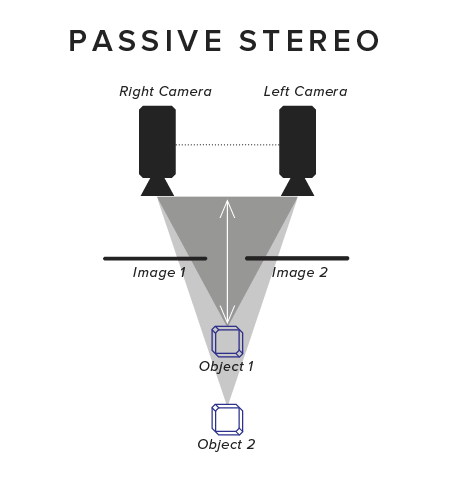
Both structured light and active stereo, as well as passive stereo, are all stereo-based solutions?�?meaning that depth estimations are based on identifying features from two different viewpoints so that they can be triangulated. It is this which implicitly gives us depth, the distance of a point from the camera along the camera viewing direction. Note that the depth estimation is stereo because of the two viewpoints needed to estimate depth, not the number of cameras (a common misconception). In the case of structured light, the projector represents one viewpoint and, due to the known projected pattern, features have to be found only in one camera view. Active and passive stereo solutions, on the other hand, need to match features from one camera to the other. Only Time of Flight does not rely on stereo principles and measures depth directly (although most often not based on time, as we will see�below).
REQUIREMENTS FOR MOBILE AR DEPTH�CAMERAS
So what are the specific requirements for depth cameras in the case of mobile AR? First, sensors need to be very small in order to integrate into headsets of comparably restricted size. For AR headsets, small can be defined as �mobile phone class sensors� in size,e.g., a camera module no more than 5mm thick. Second, the depth camera should use as little power as possible, ideally something noticeably lower than 500 mW, since the overall heat dissipation capability of the average headset is just a few watts. Third, in order to further save power, the depth camera should not require intensive processing of the sensor output since that would result in further power consumption.
Two prominent use cases for depth cameras in mobile AR today include environmental scanning (e.g. reconstruction) and user input (e.g. gesture recognition). These two use cases have largely different requirements. For environmental scanning, the depth camera needs to see as far as possible?�?in practice roughly a range of around 60 cm to 5 meters. In contrast, user input needs to work at only arm�s length, hence a range of around 20 to 100 cm. Thus, in total, we�d like to cover a range of 20 cm to 5 meters, a 25x ratio. Unfortunately, such a vast range is problematic for most depth cameras today. For example, the emission power of a projector that reaches as far as 5 meters would oversaturate the camera for objects at a distance of 20 cm. Similarly, a stereo-based solution providing meaningful accuracy at 5 meters requires a large baseline, which simultaneously makes it highly challenging to find correspondences close up. Fortunately, these two ranges usually don�t have to be supported simultaneously; although it can be advantageous for a depth camera to support pseudo-simultaneous modes alternating between short and long range modes on a per frame�basis.
Lastly, there is the matter of calibration. As with any sensor, depth cameras need to be calibrated to function properly. Mobile devices undergo a lot of physical stress over several years of usage, which can invalidate factory calibration. As automatic built-in self-calibration is not yet available, they rely on the factory calibration to remain valid over their lifetime, which can be a�problem.
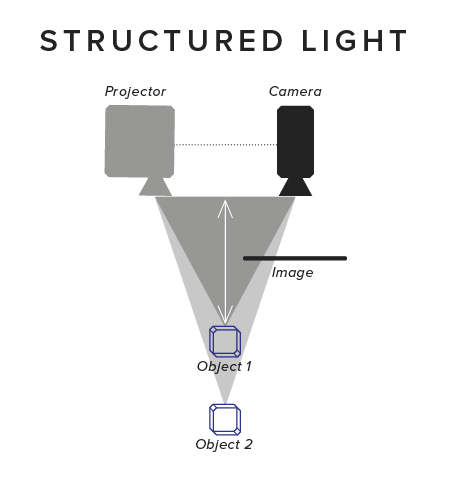
STRUCTURED LIGHT
As mentioned above, structured light (SL) projects a known pattern using a projector. The projector and camera form the stereo system, hence no second camera is required. Additionally, SL systems usually work in the infrared spectrum so that the pattern is not visible to the human eye. For safety reasons, the projector needs to be limited in projection power, usually resulting in a projection distance of up to 4�5 meters. It�s clear that there is a trade off between robustness and accuracy. For example, even though the Kinect v1 delivered VGA depth maps (~300,000 depth values), it projected a pattern with 30,000 dots only. Hence, it could also calculate only around 30,000 depth values, but used clever filtering to populate the other 90% of the depth map entries. On the positive side, by projecting only a small number of dots the projector could use a relatively large amount of energy per dot. Similarly a low number of dots allows each one to be relatively large and easily detectable in a camera image. As a result, this sensor was quite robust to difficult materials and lighting conditions. For instance, Mantis Vision?�?another depth sensor maker?�?uses a much more detailed pattern in their depth cameras that results in more detailed and more accurate depth maps. However, as users of the 2nd Tango developer device (codename Yellowstone) noticed, this depth camera was less robust than the�Kinect.
Primesense?�?the company that provided the IP for the Kinect v1?�?had a successor with codename Capri in development that was used in the first Tango device (codename Peanut). Capri was significantly smaller and more energy efficient than it�s precursor. Apple acquired Primesense and it�s believed the technology was shrunk even further to fit into the front sensor bar of the iPhone�X.
Mantis Vision�s focus is on professional structured light cameras. Their handheld scanner products F5 and the more recent F6, are the most accurate structured light cameras on the market at present. Yet form factor and cost of these devices are not suitable for integration into mobile AR headsets.
With the demise of Primesense other companies are stepping in to fill the gap. Orbbec seems to be on the rise of becoming the successor in robotics, still their sensors remain too large for integration into mobile AR�devices.
As with all stereo-based solutions, structured light can suffer from structural integrity: If the baseline is modified?�?such as due to pressure on the device?�?depth quality can quickly deteriorate to an unacceptable level. In order to achieve high quality measurements up to 5m, a baseline of ~8 cm is required. This fits tablets well, but can be challenging for mobile phones as well as for AR headsets. Also, structured light solutions optimized for environment scanning usually have a minimum sensing range of 50�70 cm preventing usage for hand tracking.
To summarize, structured light doesn�t measure depth directly, but relies on stereo matching, which is an expensive operation requiring special hardware units such as an ASIC or a DSP for real-time, low-power processing.
ACTIVE AND PASSIVE�STEREO
Active and passive stereo are quite similar in that they both rely on matching features from one camera to another. Passive stereo suffers from not being able to match uniformly colored surfaces such as white walls or empty desks that simply lack features, such as texture, to match. Active stereo overcomes this problem by projecting a random pattern onto the environment such that even textureless surfaces can be matched between the two views. However, it also means that active stereo is the most hardware component intensive solution requiring two cameras, a projector and, same as SL, most often an ASIC or DSP for real-time processing. Since the matching principle is the same, active stereo cameras have the advantage that they can usually fall back to passive stereo in situations where the pattern cannot be projected successfully, such as in outdoor lighting or over large distances.
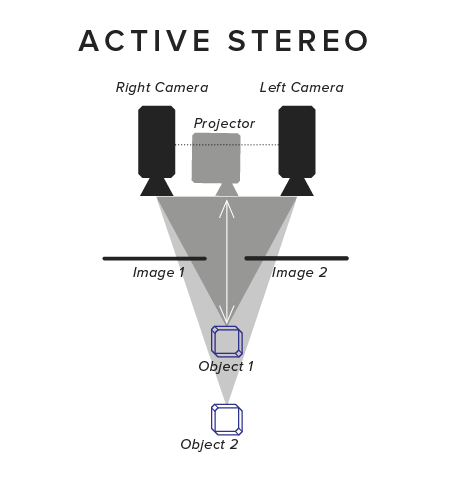
Intel�s RealSense sensor, enabling depth and IR sensing in DAQRI Smart Glasses, is a well known implementation of an active and optionally passive stereo system. Occipital recently announced their Structure Core depth sensor. While their older Structure IO sensor still uses Primesense IP, the new Structure Core sensor is a complete in-house development based on active�stereo.
One often hears arguments that passive stereo works well outdoors where untextured surfaces are rare. While that is true for use cases such as self-driving cars, a small baseline of less than 10 cm limits the distance up to which matched features can be triangulated accurately, which is not practical in most AR use cases. While it is, of course, possible to employ more than two cameras, such approaches are not suitable for mobile AR due to increased cost, size and computational complexity.
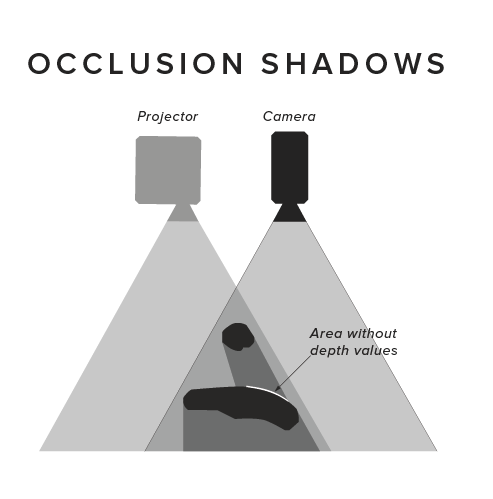
A strength of all stereo-based solutions (including structured light) is that they usually have a pretty good x/y resolution (e.g. VGA or higher resolution depth maps). If very small objects need to be identified, then that can be a significant advantage. On the other hand, all stereo-based solutions suffer from shadowing effects, which arise from the one view not observing exactly the same part of the scene as the other view: At large distances both cameras see mostly the same, but close up the two cameras can see very different parts of objects. This is like holding your finger close up between your eyes: The left eye will see the finger from the left side and the right eye will see the finger from the right side, but the overlap and hence the part for which depth could be calculated is minimal. Since depth maps are usually calculated from one camera�s point of view, this looks as if a close-up object casts a shadow on itself where no depth data is available.
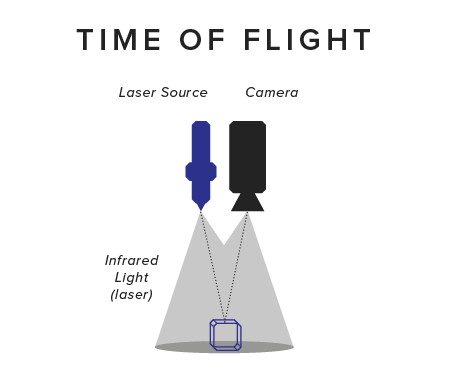
TIME OF�FLIGHT
While stereo-based solutions estimate depth by triangulating matched features, Time of Flight (ToF) cameras measure distance directly, meaning that the device measures the time offset between a signal sent out by the emitter until it arrives back at the sensor. Like stereo-based solutions, most ToF cameras today emit infrared light at 850nm wavelength, rendering it invisible to human eyes and suffer less from interference with most artificial light sources found�indoors.
Based on the measured time offset and using the known speed of light, distance can be calculated. However, due to the vast speed of light, sub-nanosecond timing accuracy is required to get accurate results. Due to technical challenges, only a few devices actually use this principle: one well-known device class are LIDAR sensors, which are popular in self-driving car research�today.
Most ToF cameras used in AR and VR today are not measuring the time of the signal, but its phase shift instead, from which distance can also be estimated (aka �continuous wave�). In order to measure phase, the emitted signal needs to be modulated (e.g. at 80MHz). However, phase cannot be measured directly but instead must be calculated from at least four measurements of the modulated infrared signal. As a result, ToF cameras record at least four so called sub-frames. These four measurements at each pixel are then combined to calculate the signal�s phase at that pixel, from which in turn distance can then be estimated.
There is an issue with this elegant method: To achieve accurate phase measurements, the signal�s phase needs to be short, yet short phases can wrap around meaning that a specific phase shift can be the result of an object at distance N, but also at distances 2N, 3N, etc. This issue in known as phase ambiguity or integer ambiguity.
For short range measurements, that is not a problem: In such a working mode the emitted infrared light is weak enough so that a signal reflected from a distance resulting in wrapping around would be too weak to be picked up by the sensor. In long range mode, a phase wrap-around can easily happen. The usual solution is to then use multiple phases to disambiguate the measurement. However, since each phase measurement requires 4 sub-frames, using two phases requires 8 sub-frames. The long time it takes to capture 8 sub-frames can lead to motion artifacts if either the depth camera or measured objects�move.
ToF depth cameras usually support mixed modes e.g. a 35Hz mode short range mode that runs simultaneously to a 5Hz long range mode by cleverly interleaving them, thereby supporting environment scanning and gesture tracking at the same time. A clear advantage of ToF cameras is that they can be very small: The measurement principle does not rely on triangulation, so there is no baseline required and emitter and sensor can be put as closely together as integration allows for. Another benefit of not requiring a baseline is that calibration is simpler and less likely to invalidate over time. Also, calculating the phase and hence the distance from four measurements requires much less processing than matching features as in stereo-based solutions.
Yet, ToF cameras are not without their shortcomings. Most obviously, ToF cameras today typically have a relatively low resolution of 100k pixels and often even lower. Also, ToF cameras suffer from multipath effects, which occurs if signals do not only reflect directly back to the sensor, but take multiple turns. Similarly, at object boundaries some of the sub-frames might measure the foreground, while others measure background surfaces resulting in artifacts. Finally, stray light (light reflecting back from very close objects such as the headset itself) can be problematic. All these issues can be dealt with up to a certain extent, but require special care when positioning the sensor or extra processing thereby reducing the computational advantage of ToF�cameras.
THE FUTURE
At present, there is no perfect depth camera?�?a fact that is unlikely to change for the foreseeable future. However, we have seen enormous progress over the last decade. The Kinect v1 was released only 7 years ago. Its technology has since been miniaturized to fit in the front sensor bar of the iPhone X. Similarly, ToF cameras have made significant progress delivering same or better quality than stereo based solutions today.
Still, all popular sensors are limited primarily to indoors usage. While ToF has a slight advantage here due to using modulated light, in strong, direct sunlight all active solutions fail. ToF camera manufacturers such as PMD have recently announced that their sensors will also support 940nm, which is known to work better outdoors than the 850nm dominantly used today. Samsung has shown similar improvements with a 940nm based structured light depth�sensor.
Another important factor is cost. Due to the huge success of color cameras in mobile phones, top quality camera modules cost only ~10$ today. Until recently, there has been no market that would support large scale and low cost production of depth sensors, but it seems this is changing and I expect depth sensor prices to come down�too.





