


(This article was co-written by my friend & colleague Mas Kono; it was originally published by TechBeacon). As a QA, QE, or testing professional, you hear some questions�frequently, especially if you�are in�a leadership�role. These include:�How many test cases are...
(This article was co-written by my friend & colleague Mas Kono; it was originally published by TechBeacon).
As a QA, QE, or testing professional, you hear some questions�frequently, especially if you�are in�a leadership�role. These include:�How many test cases are left to execute, how much longer will testing take,�and what percentage of our testing is complete?
As leaders, we are often pressed to respond�with straightforward, linear, numeric answers. In fact, this is what those asking the questions usually want�an easy-to-understand-and-digest data nugget�on which to base complex business decisions. Executives�expect answers such as, �We have 500 out of 10,000 test cases remaining,� �On average, we can do 50 test cases per day, so about 10 days,� or, �We are 95% complete.�
As those with experience have learned, however, these types of answers don�t always provide the appropriate information. Pitfalls of �just giving a number� include:
The numbers are easy to misconstrue. They don�t tell the whole story. They�re one-dimensional. They reflect outdated information.An effective way to resolve this problem is to use the�metric that one of us (Mas Kono) developed, which he calls test case points.�It�s essentially a�weighted measure of planned test case execution.�
What�leaders�really�want to know
When speaking to your�leadership about testing progress,�speak to them in their language. Most leaders don�t care about or even know about, equivalence classes, pairwise testing, or high-volume automated testing. They generally have no context that indicates the business risk associated with yet-to-be-executed tests and any�test�coverage that�s�lacking.
Talking about testing at this level of detail will obfuscate, not clarify. You�ll be giving them�information they neither need nor care about, and you won�t be�helping them make business decisions regarding the current state of the software.
What�s worse, the information you do give them, if it lacks the proper context, can lead them to make bad decisions.
Here�s what the typical executive wants to know about testing for a release:
Can we release yet? If not, how close are we to being able to release? If we release today, what are our risks? What�s the plan if something bad happens?In general, they want brief, direct, actionable information that they can use to make business decisions; they want �pass or fail��and �red or green.�
To be fair, testing organizations aren�t special in this regard; like other groups, testing organizations need to provide information that is valuable to�executives.
The origin of test case points
Around a decade ago,�Mas was a director of quality assurance and was asked to report on the percentage of test cases executed. This metric was to be used as the measure�of testing progress.�
Mas was not a fan of this metric; he knew that the number had little meaning without supporting context. It conveyed neither the amount of testing work�nor the amount of development work that remained. Additionally, it didn�t address which type of work remained.
Although�Mas hated reporting this metric, he�was compelled to do so by leadership in the absence of anything more comprehensive.
Later in the product timeline, Mas was again asked to report progress on testing; he had no recourse but to deliver a number: 80% complete. At that point, executives wanted to ship the product; they were willing to risk not testing the final 20% to get the product on the market.
There was, however, a big problem: The remaining 20% of the tests were the most important for the new features, and the code for those features had not yet been�implemented.
Mas explained this situation to the executives; naturally, they weren�t pleased that the metric didn�t reflect reality. Further, they lectured him about why the �80% done� number was a bad metric, even though Mas already knew this.�This frustration was Mas� catalyst for creating a new metric.
Test case �shelf life�
Before we explain�this new metric, you need to understand one�important concept.
As one of us (Paul Grizzaffi)�wrote in this blog post, in the world of food retailing, an expiration date is the date by which a supplier suggests you consume its product. Foods such as tortilla chips and crackers get stale; they may�not sicken or kill us, but usually, we don�t enjoy stale food, and part of the value we derive from food is enjoyment.
The food industry says these foods have a�shelf life; a product has exceeded its shelf life�once this date has passed.
Some of the tests that we perform on a release-over-release basis may also have a shelf life. Eventually, these tests become stale and are of so little value that they�either are no longer worth running or�are not worth running frequently.
This important fact�must be reflected in our metric: Some test cases and results have a time-sensitive aspect and, over time, become less important.
The point of test case�points
Mas� new metric delivers a more holistic testing status, but still offers a numerical value that�s easily digestible by executives.�
The point system works similarly to story points in Scrum, where user stories have�points so they can be sized�relative to one another. In Scrum, if Story 1 is �more work� than Story 2, then Story 1 would be assigned a higher number of points.
There are two important differences between test case points and story points.
A test case point is more complex than a unit of work; it is a unit of work plus some additional, context-sensitive facets explained below. The points assigned to a test case can change over time, in part because the value of the test case being executed can change�for instance,�it gets closer to the end of its shelf life, or the feature it exercises gets modified.How test case points work
Not all test cases are created equal. Some have a higher priority, some require a lot more effort or duration, and the importance of a test case can change over the life of a product. To capture these factors in test case points, we give numeric values to test cases based on several different�attributes.
Static�attributes don�t typically change over the life of a test case. Some examples include:
Functional area (e.g., purchase, messaging, profile management) Coverage type (e.g., happy path, negative, boundary) Complexity (e.g., low, medium, high) Effort (e.g., low, medium, high)Your product�s code can change over time, so some test case attributes might also change over time; these changes are called �active attributes.� Some examples include:
Categorization (e.g., new feature, smoke, regression) Priority (e.g., critical, high, medium, low) Release importance (e.g., critical, high, medium, low) Execution frequency (e.g., after every build, after every deploy)Each value for each attribute has points associated with it. To determine the test case points associated with a single test case, add up the point values for each of its attributes; to determine the test case point total for a particular set of test cases�for instance, a regression test suite�add up all the point values for each of those test cases.
The �release importance��attribute needs explanation. Clearly, when code associated with a functional area has changed, its release importance�is likely to have a higher number of points. What may not be so obvious is that, if the code is changed in a different�but related area of the code, the dependent code�s test case may have a higher release importance�as well.�
Here�s a simple example: A�one-line change in a highly�shared component of your�application could necessitate running a larger number of test cases than would have been executed if that execution was only triggered in isolation.�
How attribute points are decided
How points are assigned to specific attribute values is context-dependent. Different organizations have different attributes and will value those attributes differently. Every organization needs to decide how to assign points�to its attributes.
The points�assigned to each attribute and, therefore, to each test case matter. By using a point-based approach, the impact of each test case can be coarsely communicated; facilitating this communication is the intent of test case points. The points matter because they convey the relative impact of each test case.
Paradoxically, the points that are assigned to each attribute, and therefore to each test case, do not matter. The intent of this approach is not to debate whether Test Case 668 should really have 47% more points than Test Case 667. That would be like a Scrum team debating whether Story 668 should really have 47% more story points than Story 667.
It�s not a valuable debate because it�s not about being exactly right on each test case; it�s about being right on average, where sometimes the estimate will be high and sometimes it will be low.
Here�s an example
Consider an e-commerce website. The ability to purchase a product using a credit card is one of the highest-priority test cases; this test case would be executed at least once per release, and probably once per deploy to pre-production environments.
If this e-commerce company introduced a new feature�for example, the ability to message another customer�running test cases to check the condition of that feature would be a high priority for at least the first release in which that feature is included. It may even have the same priority as purchasing via credit card for that first release.
Over time, however, testing the messaging feature becomes a lower priority compared to testing purchasing via credit card. This happens because selling products is the core of the company�s business, but the messaging feature, while important to the company, is not. In other words, if the test team was running short on time and had to skip some test cases, it would likely skip messaging, not purchasing.
To see how test case points might be applied in�this example, consider the following test case point breakdown:
| Attribute | Value | Points | Value | Points | Value | Points |
| Functional Area | Purchase | 10 | Messaging | 2 | Profile | 3 |
| Coverage Type | Happy Path | 5 | Negative | 3 | Boundary | 4 |
| Complexity | Low | 2 | Medium | 4 | High | 6 |
| Effort | Low | 3 | Medium | 6 | High | 9 |
| Characterization | New Feature | 9 | Smoke | 6 | Regression | 3 |
| Priority | Low | 3 | Medium | 6 | High | 9 |
| Release Importance | Low | 3 | Medium | 6 | High | 9 |
�
Now consider these two test cases and the points assigned to their attributes for the first release that will contain the �message another customer��feature:
Test Case�1�Purchase with a credit card
| Attribute | Value | Points |
| Functional Area | Purchase | 10 |
| Coverage Type | Happy Path | 5 |
| Complexity | Low | 2 |
| Effort | Low | 3 |
| Characterization | Regression | 3 |
| Priority | High | 9 |
| Release Importance | High | 9 |
| Total Points | 41 | |
Test Case�2�Send a message to another customer
| Attribute | Value | Points |
| Functional Area | Messaging | 2 |
| Coverage Type | Happy Path | 5 |
| Complexity | Low | 2 |
| Effort | Low | 3 |
| Characterization | New Feature | 9 |
| Priority | High | 9 |
| Release Importance | High | 9 |
| Total points | 39 | |
As you can�see�by each test case�s point totals, for the initial release of the messaging feature, the new feature�s test case point total (Test Case�2) is almost as high as the total for purchasing with a credit card (Test Case 1). This is because testing the new feature is almost as important as testing a core feature.
Now consider a subsequent release. �Purchase with a credit card��is already in the regression testing suite, and since none of its other attributes have changed, its point total remains unchanged. This is one of the core features of any e-commerce website.
�Sending a message��is no longer a new feature, but the organization still deems it important enough to test; this fact changes some of Test Case 2�s active attributes, namely characterization, priority, and release importance.
The change in these attributes also causes�the point total to change. The table below reflects these changes:
Test Case�2�Send a message to another customer
| Attribute | Value | Points |
| Functional Area | Messaging | 2 |
| Coverage Type | Happy Path | 5 |
| Complexity | Low | 2 |
| Effort | Low | 3 |
| Characterization | Regression | 3 |
| Priority | Medium | 6 |
| Release Importance | Medium | 6 |
| Total Points | 27 | |
Notice that the total points for Test Case�2 are now significantly smaller than those for�Test Case�1, reflecting Test Case�2�s new, relative position in the criticality of test cases. In other words, Test Case 2�s importance to the upcoming release is less�than that of Test Case�1. Logically, we should expect this because purchasing will always be more important to the business than messaging.
How points are used to communicate status
To review, test case points came about to provide a metric that communicates more context than traditional numeric metrics can provide. The points for each test case you want to�run for a specific testing event, such as a release, are totaled. This total provides one view into the amount of testing�that needs to be performed for the current release or testing cycle. Once testing starts, points are burned�down, much the way you burn down story points in Scrum.
You can determine three�things just by looking at a test case points burn-down chart:
Whether all test cases have been executed A rough estimate of how much testing remains, provided there are no issues that require a significant retest A rough estimate of how much retesting has occurredA key reason why the test case points approach works is that the highest-point test cases can be identified and executed first. Why is this important? See the graphs below.

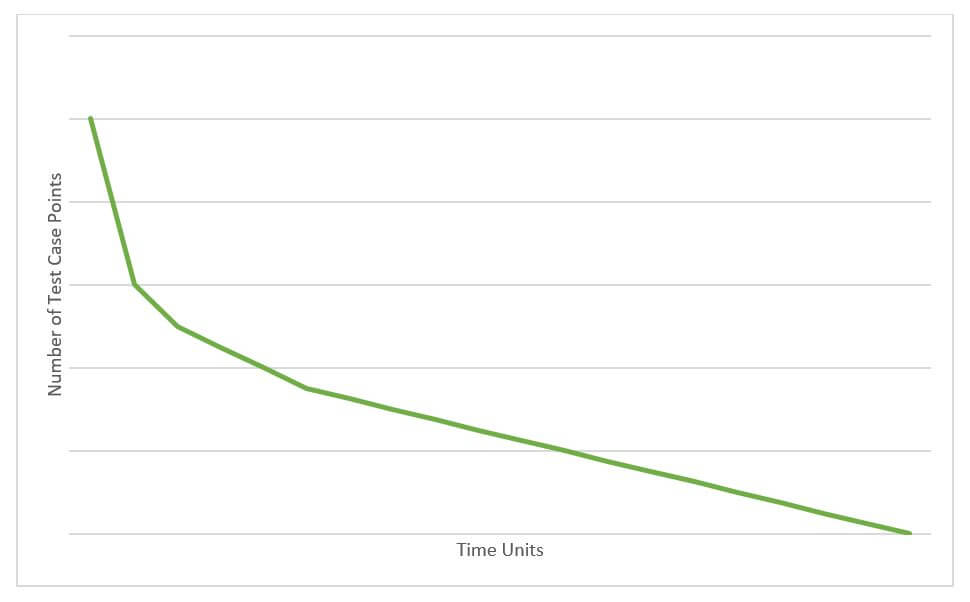
Figure 1. Ideal burn-down�graph.
In the graph above, you see the ideal burn-down, which can be achieved by executing the highest-point-value test cases first. Executing those test cases first makes sense because�higher-point�test cases will generally be more important�to the current release since that�s the way you�assigned the points in the first place.
Knowing the results of these test cases early is beneficial because you can discover issues with the most important features, i.e., the higher-pointed ones,�sooner.

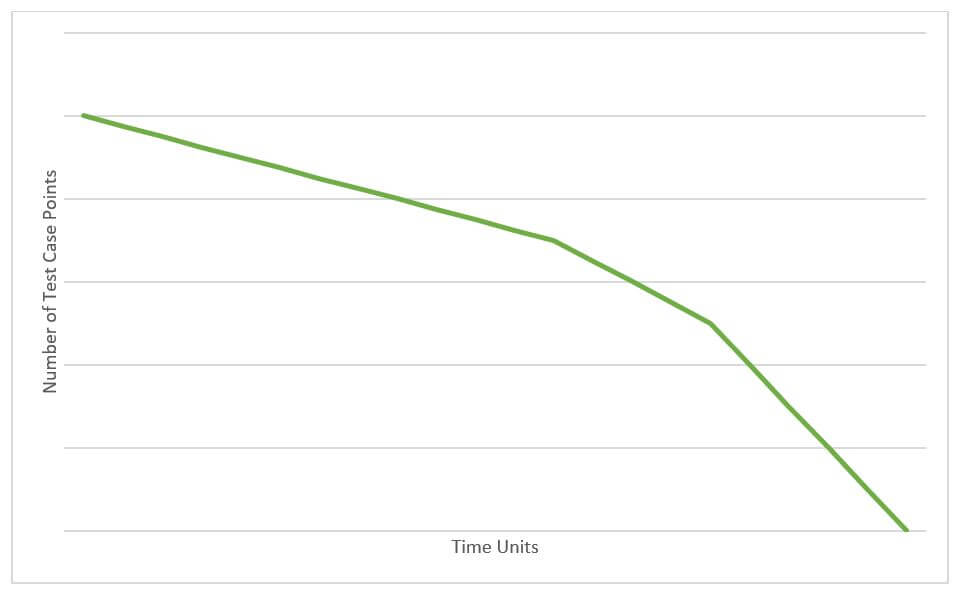
Figure 2. A�less-than-ideal burn-down graph.
In the graph above,�progress is less than ideal because you burn down slower at first and faster at the end. This typically indicates that you chose smaller-pointed test cases earlier, leaving the higher-pointed, i.e., more valuable, test cases until later in the cycle. This can cause you to find issues with critical product features later in the cycle, when they may be harder to address.

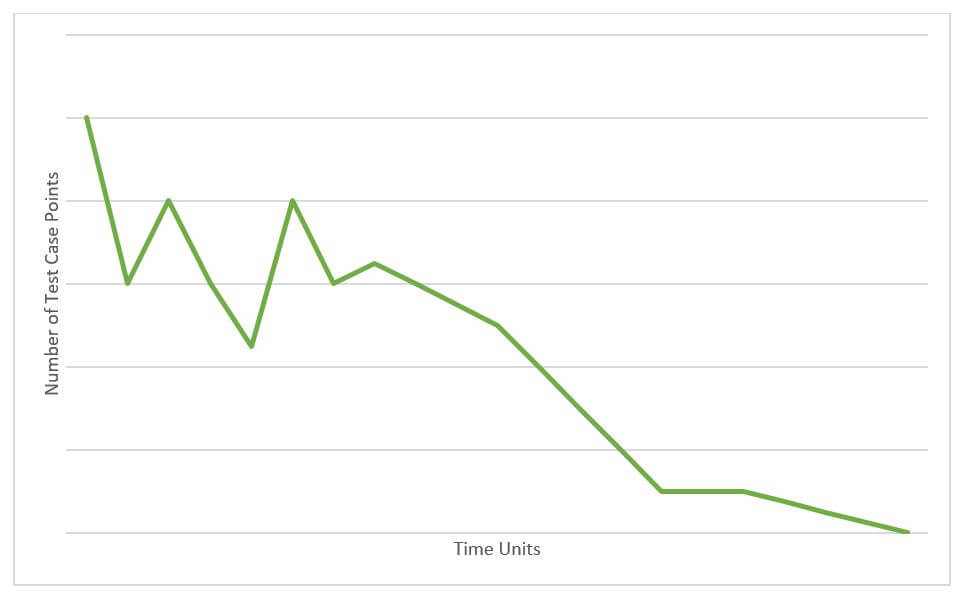
Figure 3. A typical burn-down graph.
The reality, however, is that a typical workflow looks more like the graph above. Testing usually starts off well, and then finds an issue. Once the issue is resolved, the fix often requires rerunning more than just the test case that uncovered the issue. And�this causes the remaining test case points to spike back up because you now have more work to do.
Next, more progress is made, then more issues are detected, causing your test case points total to rise again. Over time, you�ll uncover fewer issues and, typically, the magnitudes will be smaller. Why? Because you started with the high-impact, high-criticality test cases; you likely uncovered the high-impact, highly critical issues earlier in your testing.
Why this works
In part, the test case points approach works because the metrics it conveys are not based on the comparison of entities (i.e., test cases) that are unequal, both in the effort required�and in the importance of the work.
So how might things�have gone for Mas had he been using test case points�back in the early�2000s?�When asked for a completion percentage, he would have given a more telling number, say 50% complete; since this percentage is based on completed test case points, as opposed to completed test cases, the number itself gives a more realistic view of the amount of remaining work. This kind of metric helps frame the subsequent conversations about the content of the remaining work.
Test case points�can�t stand alone
The preceding example is just that,�an example. There is no prescriptive way to choose test case attributes, and there are no firm guidelines as to�which values to assign to them. Each organization should craft its points usage as is appropriate for that organization.
Test case points are a tool; they are not�the�metric. They are a way to help deliver usable information in an audience-appropriate manner, but they are not enough to deliver all the salient parts of the testing situation.
Test case points are not a cure-all for test reporting or metrics problems. Organizations whose reporting and metrics program�already provides�the appropriate information to the appropriate stakeholders may not require a wholesale switch to test case points.
But if your organization is�having issues with reporting or metrics, it may benefit from the test case points framework.
To use a baseball analogy, looking only at the �test cases executed��metric is a lot like batting average for a baseball player.�It�s useful, but isn�t �batting average with runners in scoring position��a better metric with a bit more information?�
This is what test case�points are like; they are additional context wrapped in a single number.�And, in business, isn�t context everything?
Like this? Catch me at or book me for an�upcoming event!









{kind=link}
{kind=link}
{kind=link}