The Machinery of Mobility Intelligence
Let’s look at examples of demand discovery questions:
EV charging operator: Where should I spend $650,000 to set up my next EV charging station in the city, and how many AC and DC chargers should I place there?
e-bike operator: I want to expand my service to another city. How should I prioritize my first 20 bike stations there, and how many docking points should I include in each?
Urban planner: I’ve got EV charging operators and micromobility operators on my back wanting to expand their services to maximize their profits – but I’m more concerned with ensuring my city-dwellers can get around as easily as possible. What sites in the city should I allocate for these services?
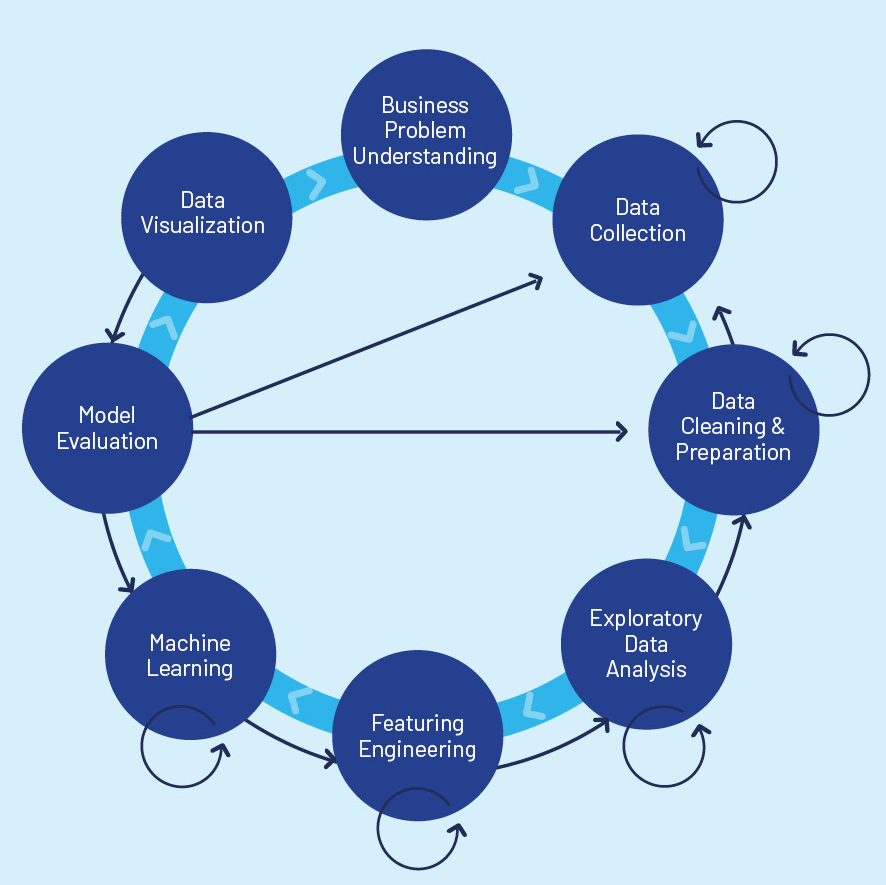
Answering those burning questions is an extremely complex process. We need to come up with the best answers through a formula in the following format:
Demand = f(X1, X2, … Xn)
In data science, “Demand” is known as the “label” and parameters X1, X2, … Xn are known as “features.”
Before we even start figuring out the formula, we need to make sure the data we are using is cleaned of outliers or errors and enriched to ensure that all data points are complete and coherent (if the GPS coordinates of a shopping mall place it in the middle of a lake, we’d question the validity of that data point).
Once we have confidence in our core data, we can start building the formula. We need to figure out which features affect demand, and the relationship between the different features. A typical workflow will start with a minimal set of features in a simplistic relationship model. We then apply the model to a known data set and see how accurately the model predicts demand. In early stages, we will usually be way off, and must evaluate how to change the feature set, or the model to improve predictions. This is where the data science behind mobility intelligence becomes somewhat of an art because there’s no “one size fits all” in mobility intelligence. Predicting demand for EV charging stations is quite different from predicting demand for e-scooters. Moreover, the demand model for EV charging in one region may be different from the corresponding model in another region. In practice, demand models may involve dozens of features assembled from many different data sources and assembled into complex formulae. And to complicate the process even more, you can only be sure a model is valid at the time it was formulated. As the world evolves and parameters change, machine learning models that predict demand or any other label must be re-evaluated periodically to ensure they can continue to make accurate predictions.
Finally, we’ll arrive at a demand model that has an acceptably low degree of error when applied to our known data set. The model will typically be much more complex than what we started with.